Introduction
The landscape of full-stack development is in a perpetual state of evolution, with new tools, libraries, and best practices emerging at a rapid pace. For modern JavaScript developers aiming to build scalable, efficient, and maintainable applications, navigating this dynamic environment can be challenging. This report provides a detailed and structured guide to leveraging a powerful combination of technologies: React for frontend development, Next.js as a React framework, Express.js for backend services, and Supabase as a backend-as-a-service (BaaS) solution. Furthermore, it explores how AI-assisted tools like Cursor can significantly accelerate the development workflow.
This document is aimed at developers with intermediate experience, particularly those focused on scaling their applications. It delves into best practices, identifies key libraries, and offers guidelines for each component of this stack, as well as general principles for robust full-stack development. The insights provided herein are geared towards enabling developers to make informed decisions, optimize their development processes, and ultimately build high-quality software that meets the demands of 2025 and beyond. Each section will provide comprehensive guidelines, focusing on practical application and strategic considerations rather than specific code implementations, to foster a deeper understanding of the underlying principles.
1. Best Libraries for React in 2025: Powering Scalable Applications
Choosing the right libraries is paramount when building scalable and efficient React applications in 2025. The React ecosystem is vast and dynamic, offering a multitude of options for various concerns, from state management and data fetching to UI components and animations. This section identifies and evaluates widely adopted and powerful libraries, focusing on their suitability for large-scale projects where performance, maintainability, and developer experience are critical. For each library or category, we will explore its primary use cases, advantages and disadvantages, integration insights, and performance implications, always with an eye toward building applications that can grow and adapt.
State Management: Taming Complexity at Scale
Effective state management is a cornerstone of any scalable React application. As applications grow, managing shared data, component-level state, and server cache becomes increasingly complex. React’s built-in solutions like useState and useReducer are excellent for local component state. The useContext API can share state across the component tree, but for extensive global state in large applications, it can lead to performance bottlenecks due to unnecessary re-renders if not managed carefully. Therefore, dedicated global state management libraries are often indispensable.
Zustand has rapidly gained popularity and is often considered a go-to solution for global state management in modern React applications.
- Use Case: Managing complex global application state in a simple, unopinionated, and scalable manner. It’s suitable for applications of all sizes but shines where Redux might feel like overkill or when a more minimalistic API is preferred.
- Pros:
- Simplicity and Minimal Boilerplate: Zustand offers a very concise API, making it easy to learn and integrate.
- Performance: It’s designed to be performant, typically causing re-renders only in components that subscribe to specific parts of the state.
- Flexibility: Being unopinionated, it doesn’t impose a rigid structure, allowing developers to organize stores as they see fit.
- React Hooks-based: Its API feels natural within a React hooks paradigm.
- Cons:
- Less Opinionated: While a pro for some, the lack of strong opinions might lead to inconsistencies in very large teams if clear conventions aren’t established.
- Smaller Ecosystem (Compared to Redux): While growing, its ecosystem of middleware and developer tools is not as extensive as Redux’s, though often sufficient.
- Integration Tips: Zustand can be introduced incrementally. Start by managing small pieces of global state and expand its usage as needed. Its hook-based nature makes it easy to consume state within any functional component.
- Performance Considerations: Generally very performant due to selective re-renders. Ensure that components only subscribe to the state slices they need to avoid unnecessary updates.
Redux Toolkit (RTK) remains a robust and widely adopted solution, especially in enterprise-grade applications and projects with existing Redux codebases.
- Use Case: Managing complex and centralized application state, particularly in large applications requiring a predictable state container, extensive developer tooling, and a rich ecosystem of middleware.
- Pros:
- Predictable State Management: Follows the core Redux principles (single source of truth, state is read-only, changes made with pure functions).
- Excellent DevTools: Redux DevTools provide powerful debugging capabilities.
- Large Ecosystem: A vast array of middleware, add-ons, and community support.
- Opinionated Structure: RTK simplifies Redux by providing sensible defaults and reducing boilerplate, guiding developers towards best practices.
- RTK Query: Its integrated data fetching and caching solution is a significant advantage for managing server state.
- Cons:
- Boilerplate: Even with RTK, there can still be more boilerplate compared to libraries like Zustand.
- Learning Curve: Understanding Redux concepts (actions, reducers, store, middleware) can have a steeper learning curve for beginners.
- Integration Tips: RTK encourages a feature-folder or ducks pattern for organizing Redux logic. Leverage
createSliceto simplify reducer and action creation. RTK Query can be adopted for new data fetching needs even in existing Redux projects. - Performance Considerations: While Redux itself is performant, poorly structured selectors or excessive updates to large state objects can cause performance issues. Memoized selectors (e.g., with Reselect) are crucial for optimizing performance in connected components. RTK Query helps manage the performance aspects of server state.
Other notable alternatives include Jotai and Valtio for atomic state management, which can be beneficial for fine-grained state updates and offer a different paradigm that might suit certain application architectures focused on scalability through modularity.
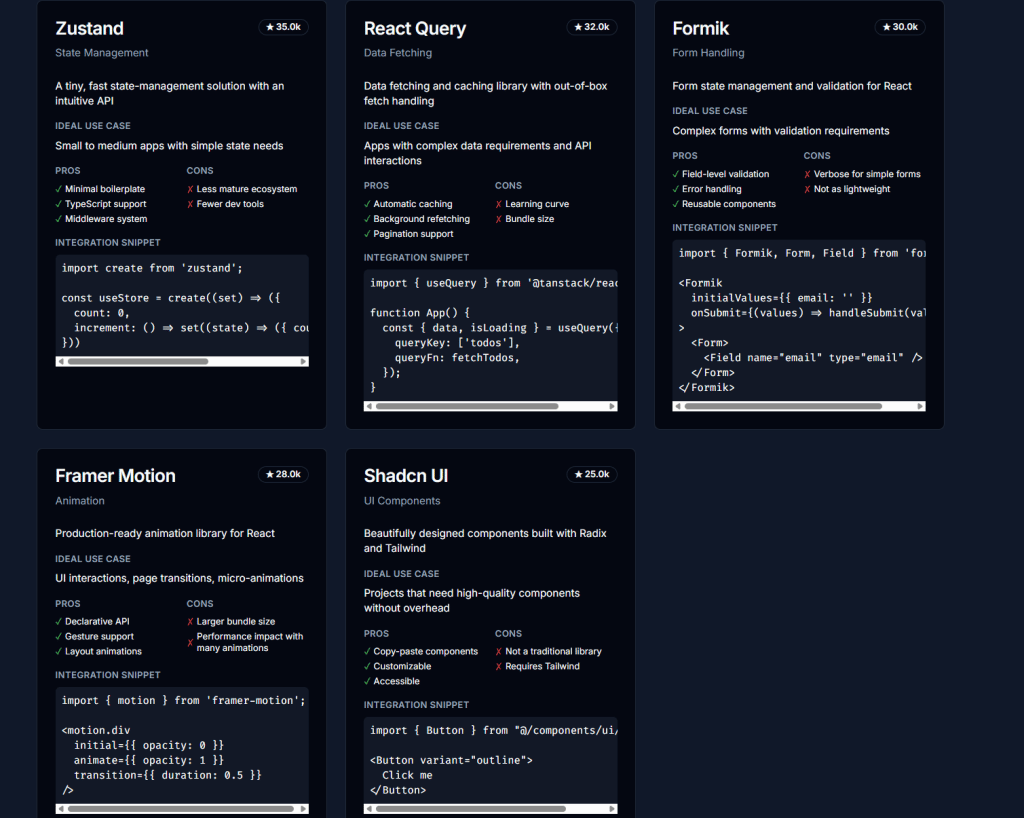
Data Fetching and Caching: Bridging Client and Server Efficiently
Fetching, caching, and synchronizing data from servers is a critical aspect of modern web applications. For scalable applications, robust data fetching strategies are essential to ensure good performance, reduce server load, and provide a smooth user experience.
TanStack Query (formerly React Query) is a dominant force in this space, highly recommended for managing server state.
- Use Case: Fetching, caching, synchronizing, and updating server state in React applications. It’s not a global state manager for client state but excels at handling asynchronous data from APIs.
- Pros:
- Declarative Data Fetching: Simplifies data fetching logic within components.
- Automatic Caching: Intelligent caching mechanisms out-of-the-box (e.g., stale-while-revalidate).
- Background Updates & Refetching: Keeps data fresh automatically (e.g., on window refocus, interval refetching).
- Optimistic Updates: Improves perceived performance by updating UI before server confirmation.
- Pagination and Infinite Scroll Support: Built-in utilities for common UI patterns.
- DevTools: Excellent developer tools for inspecting query states and cache.
- Cons:
- Learning Curve: While powerful, understanding all its concepts and configuration options can take time.
- Client-Side Focus: Primarily for managing server state on the client; for server-side data fetching strategies, framework features (like in Next.js) are often used in conjunction.
- Integration Tips: Integrate TanStack Query early in the project. Define clear query keys for effective caching and invalidation. Use its
QueryClientProviderat the root of your application. It pairs well withfetch, Axios, or GraphQL clients. - Performance Considerations: Significantly improves performance by reducing redundant data fetches through caching. Background updates ensure data freshness without blocking UI. Careful management of query keys and cache invalidation is important for optimal behavior in large applications.
For applications utilizing GraphQL, dedicated clients like Apollo Client or urql are standard choices.
- Apollo Client:
- Use Case: Building complex, data-driven applications with GraphQL, offering robust caching, state management, and integration with React.
- Pros: Feature-rich, strong community, powerful caching capabilities, local state management features.
- Cons: Can be complex to set up and configure for simpler use cases. Larger bundle size compared to urql.
- urql:
- Use Case: A lightweight and extensible GraphQL client, suitable for projects that need a simpler GraphQL client or want more control over its behavior through exchanges.
- Pros: Smaller bundle size, simpler API, highly extensible via its “exchanges” concept.
- Cons: Fewer built-in features compared to Apollo Client, might require more custom setup for advanced caching or local state management.
- Integration Tips (GraphQL Clients): Wrap your application with the respective provider. Utilize hooks provided by the libraries to fetch data and perform mutations. Understand their caching strategies (e.g., normalized cache in Apollo) for optimal performance.
- Performance Considerations (GraphQL Clients): Caching is key. Normalized caches can significantly reduce data fetching and improve UI consistency. Be mindful of query complexity and data requested to avoid over-fetching, even with GraphQL.
React Server Components (RSCs) and Server Actions/Functions, particularly within frameworks like Next.js, are transforming data fetching by allowing data to be fetched directly on the server as part of the component rendering lifecycle. This approach can reduce client-side JavaScript, improve initial load times, and simplify data fetching logic for components that primarily display server-rendered data. For scalable applications, leveraging RSCs can lead to significant performance gains and a better separation of concerns.
UI Component Libraries: Accelerating Development with Style and Consistency
UI component libraries provide pre-built and often customizable components, speeding up development and ensuring UI consistency. The choice often depends on the desired level of customization and whether a specific design system is being followed.
Headless UI Libraries are gaining immense traction for scalable applications requiring custom design systems.
- shadcn/ui:
- Use Case: A collection of beautifully designed, accessible, and unstyled components that you copy and paste into your project, built using Radix UI and Tailwind CSS. It’s not a dependency in the traditional sense.
- Pros: Full ownership of the code, highly customizable, excellent design and accessibility, integrates seamlessly with Tailwind CSS, promotes building your own component library.
- Cons: Requires manual updates if the upstream components change (as you own the code). Initial setup involves copying components.
- Integration Tips: Use the CLI to add components as needed. Customize them directly within your project to match your design system.
- Performance Considerations: Since you only include the components you use and they are typically well-optimized (often using Radix primitives), performance is generally excellent.
- Radix UI:
- Use Case: Provides a set of unstyled, accessible, and highly functional component primitives (e.g., dropdowns, dialogs, tooltips) to build your own design system.
- Pros: Excellent accessibility, unstyled by default (full styling control), great API design, focuses on behavior and interaction.
- Cons: Requires you to implement all styling yourself.
- Integration Tips: Combine with Tailwind CSS or other styling solutions. Use it as the foundation for your custom component library.
- Performance Considerations: Primitives are generally lightweight and performant.
- React Aria (Adobe):
- Use Case: Similar to Radix UI, it provides hooks and components for building accessible custom UI components and design systems, with a strong focus on WAI-ARIA patterns.
- Pros: Deep focus on accessibility and internationalization, granular control over behavior and styling.
- Cons: Can have a steeper learning curve due to its comprehensive nature and focus on low-level details.
- Integration Tips: Ideal for teams building highly bespoke and accessible design systems from the ground up.
- Performance Considerations: Performance is generally good as it provides the behavioral logic, leaving rendering and styling optimization to the developer.
Full (Styled) Component Libraries like Material UI (MUI), Mantine UI, and Chakra UI continue to be popular for rapid development when a pre-existing design system is acceptable or desired.
- Use Case: Quickly building UIs with a consistent look and feel, leveraging a comprehensive set of ready-to-use components.
- Pros: Large set of components, often good documentation, theming capabilities, can significantly speed up initial development.
- Cons: Can be harder to customize extensively to match unique brand identities. Bundle size can be a concern if not managed carefully (tree-shaking is important).
- Integration Tips: Utilize their theming systems for customization. Only import components you use to aid tree-shaking.
- Performance Considerations: Pay attention to bundle size. Some libraries offer better tree-shaking than others. Virtualization might be needed for very long lists rendered with library components.
For scalable applications, the trend is towards headless UI libraries combined with a utility-first CSS framework like Tailwind CSS. This approach offers the best balance of development speed, customization, maintainability, and performance, allowing teams to build and evolve a unique and consistent design system.
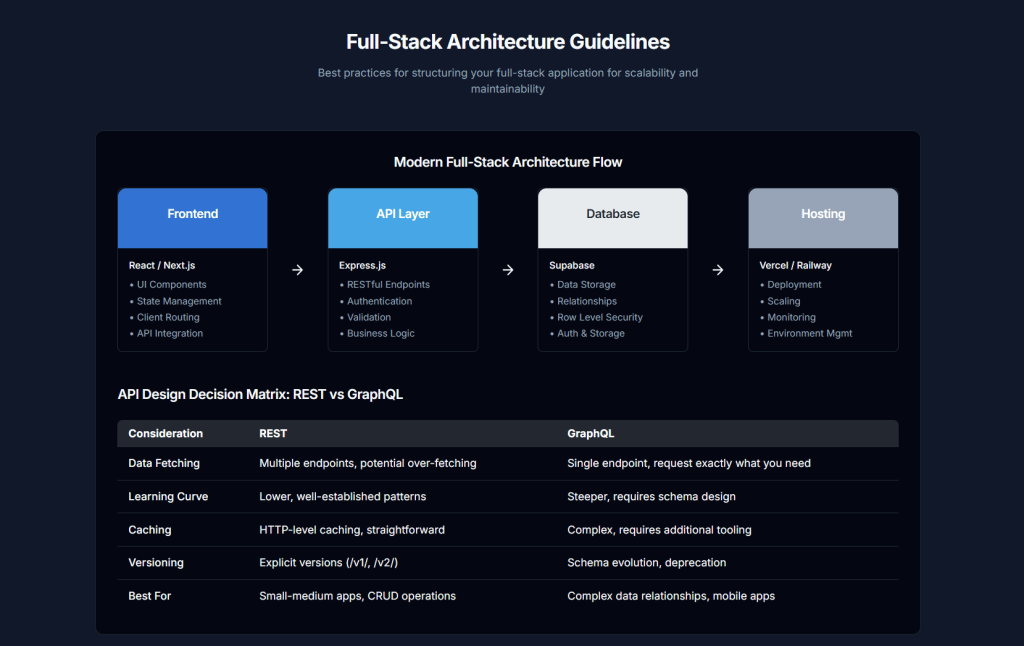
NextJS Best Practices 2025
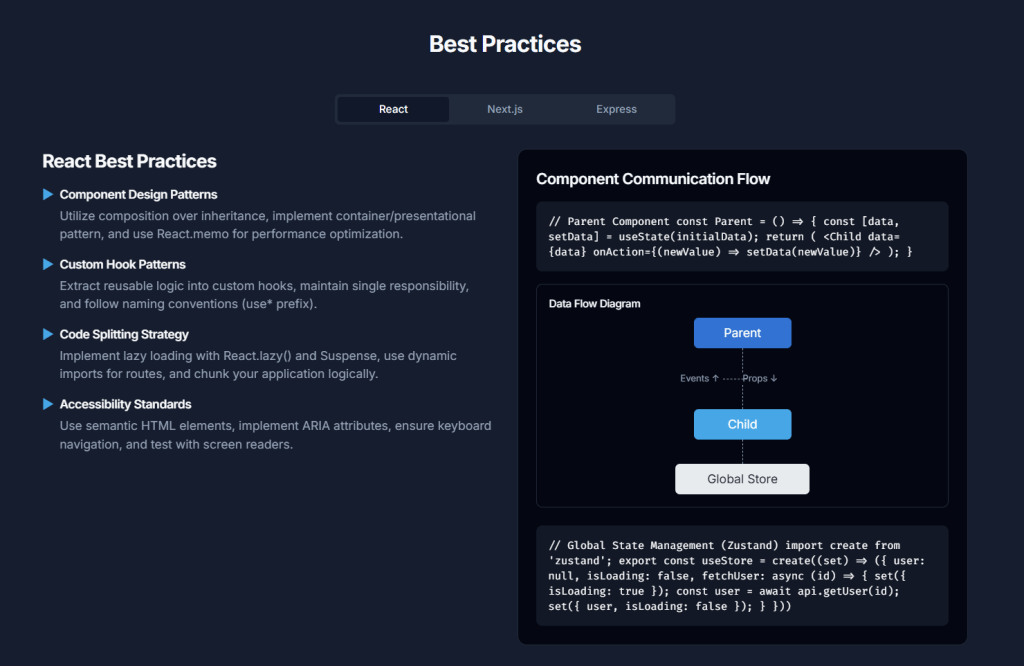
1. Folder Structure and Routing Conventions
Next.js uses a file-system based router. The structure of your app directory (for App Router) or pages directory (for Pages Router) defines your application’s routes.
Key Conventions (App Router – app directory):
- Top-Level Folders:
app: Contains all routes, components, and logic for the App Router.public: Stores static assets like images, fonts, etc., that are served directly.src(optional): Can be used to store application code, including theappdirectory, to separate it from project configuration files at the root.
- Routing Files: Special files define UI for route segments:
layout.jsorlayout.tsx: Defines a UI that is shared across multiple routes. Layouts can be nested.page.jsorpage.tsx: Defines the unique UI of a route segment and makes the path publicly accessible.loading.jsorloading.tsx: Creates loading UI using React Suspense for a route segment.not-found.jsornot-found.tsx: Creates UI for when a resource is not found.error.jsorerror.tsx: Creates UI for JavaScript errors within a route segment, acting as a React Error Boundary.global-error.jsorglobal-error.tsx: Similar toerror.jsbut specifically for the rootlayout.js.route.jsorroute.ts: Allows creating API endpoints within theappdirectory.template.jsortemplate.tsx: Similar to layouts but re-creates a new instance for each child on navigation.default.jsordefault.tsx: Fallback UI for parallel routes when Next.js cannot recover a slot’s active state.
- Nested Routes: Created by nesting folders within the
appdirectory. Each folder maps to a URL segment. - Dynamic Routes: Created by naming folders with square brackets (e.g.,
[slug],[...catchAll],[[...optionalCatchAll]]). - Route Groups (
(folder)): Organize routes without affecting the URL path (e.g.,(marketing)/aboutmaps to/about). Useful for:- Organizing routes by section (e.g.,
(admin),(shop)). - Creating multiple nested layouts in the same route segment level, including multiple root layouts.
- Adding a layout to a subset of routes.
- Organizing routes by section (e.g.,
- Private Folders (
_folder): Opt a folder and all its child segments out of routing. Useful for colocation of internal logic, components, or utilities that shouldn’t be routable. - Parallel Routes (
@folder): Allows simultaneously rendering one or more pages within the same layout. Useful for dashboards or feeds with independent sections. - Intercepted Routes (
(.)folder,(..)folder,(..)(..)folder,(...)folder): Allows loading a route from another part of your application within the current layout, often used for modals or lightboxes while keeping the context of the underlying page.
Organizing Your Project:
Next.js is unopinionated, but common strategies include:
- Store project files outside of
app: Keepapppurely for routing, with components, lib, utils, etc., in root-level folders (e.g.,src/components,src/lib). - Store project files in top-level folders inside
app: Create shared folders likeapp/components,app/lib. - Split project files by feature or route (Colocation): Store globally shared code in root
appand more specific code within the route segments that use them. Project files can be safely colocated inside route segments without being routable unless they are special files likepage.jsorroute.js.- Private folders (
_components,_lib) can be used within route segments for better organization.
- Private folders (
- Using the
srcDirectory: Many projects opt to place theappdirectory (and other application code likecomponents,lib) inside a top-levelsrcdirectory to separate application code from project configuration files (e.g.,next.config.js,tsconfig.json).
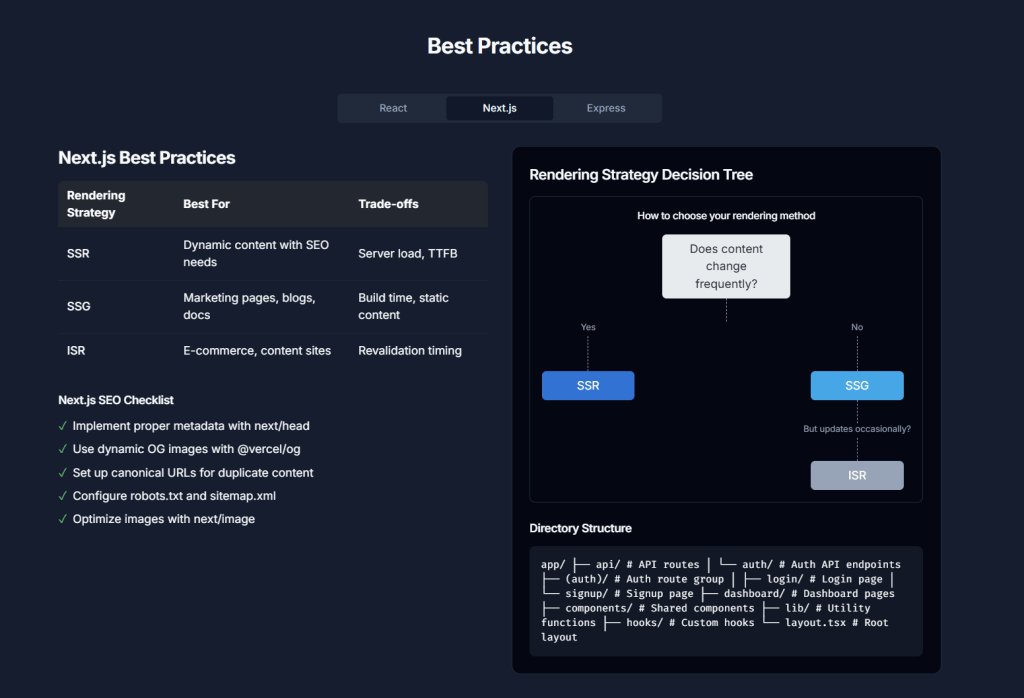
2. Static vs. Server-Side Rendering: When to Use Which
Next.js offers various rendering strategies, allowing developers to choose the best approach per page or even per component.
- Static Site Generation (SSG): (Default for App Router if no dynamic functions or data fetching is used)
- How it works: HTML is generated at build time. When a user requests the page, the pre-rendered HTML is served from a CDN, making it very fast.
- When to use: Ideal for pages where content doesn’t change often or can be pre-rendered for all users. Examples: marketing pages, blog posts, product listings, documentation.
- Pros: Extremely fast (CDN edge caching), good for SEO, reduced server load.
- Cons: Requires a rebuild and redeploy for content updates (unless using ISR).
- Server-Side Rendering (SSR): (Opt-in by using dynamic functions like
cookies(),headers(), or dynamic data fetching withcache: 'no-store')- How it works: HTML is generated on the server for each request. The server fetches data, renders the page, and sends the HTML to the client.
- When to use: For pages with highly dynamic content that changes frequently or is personalized for each user. Examples: user dashboards, e-commerce order pages, pages with real-time data.
- Pros: Always serves fresh data, good for SEO (search engines get fully rendered HTML).
- Cons: Slower than SSG (server needs to render on each request), higher server load.
- Client-Side Rendering (CSR): (Achieved by using React Hooks like
useEffectfor data fetching within components marked with'use client')- How it works: An initial empty HTML shell is served, and JavaScript fetches data and renders content in the browser.
- When to use: For parts of a page that are highly interactive and don’t need to be SEO-indexed directly, or for user-specific content within an otherwise static page. Often used in conjunction with SSG/SSR for the main page shell.
- Pros: Rich interactivity, can offload rendering to the client.
- Cons: Can be bad for SEO if not implemented carefully (search engines might not see content), initial load might show a loading state.
- Incremental Static Regeneration (ISR):
- How it works: Combines the benefits of SSG with dynamic data. Pages are generated statically at build time, but can be re-generated in the background after a certain time interval (
revalidateoption) or on-demand when data changes. - When to use: For pages that benefit from static speed but need to update periodically without a full rebuild. Examples: blog posts that get comments, e-commerce product pages with changing prices/stock.
- Pros: Fast initial loads (like SSG), content can be updated without redeploying, scales well.
- Cons: Content might be slightly stale between revalidation periods.
- How it works: Combines the benefits of SSG with dynamic data. Pages are generated statically at build time, but can be re-generated in the background after a certain time interval (
Choosing the Right Strategy (Scalability Focus):
- Default to Static: For most content, aim for static generation (SSG or ISR) for best performance and scalability. CDNs handle the load effectively.
- Use SSR Sparingly: Reserve SSR for pages that absolutely require real-time, personalized data that cannot be handled by client-side fetching on a static shell or ISR.
- Leverage ISR: ISR is a powerful tool for scaling sites with frequently updated content. It balances static performance with data freshness.
- React Server Components (RSC) (App Router Default): Allow fetching data on the server by default, reducing client-side JavaScript and improving performance. Components are server-rendered unless explicitly marked with
'use client'.
3. API Routes, Middleware, and Edge Functions
- API Routes:
- How they work: Create backend API endpoints as JavaScript/TypeScript files within the
appdirectory (usingroute.jsorroute.ts) orpages/apidirectory (Pages Router). These are serverless functions. - Use cases: Handling form submissions, database interactions, authentication, integrating with third-party services.
- Best Practices: Keep them focused (single responsibility), validate input, handle errors gracefully, secure sensitive endpoints.
- How they work: Create backend API endpoints as JavaScript/TypeScript files within the
- Middleware (
middleware.jsormiddleware.tsat the root or insrc):- How it works: Code that runs before a request is completed. Based on the incoming request, you can modify the response by rewriting, redirecting, adding headers, or streaming.
- Use cases: Authentication/authorization, A/B testing, localization (redirecting based on geo/locale), bot protection, feature flags.
- Runtime: Runs on the Edge (Vercel Edge Functions by default), making it very fast.
- Best Practices: Keep middleware lean and fast as it runs on every matching request. Avoid complex synchronous operations.
- Edge Functions:
- How they work: Serverless functions that run at the Edge network, closer to the user. API Routes and Middleware can be deployed as Edge Functions.
- Use cases: Same as API Routes and Middleware, but with the benefit of low latency due to geographical distribution.
- Pros: Low latency, globally distributed, scales automatically.
- Cons: Some Node.js APIs are not available (uses a subset of browser APIs and a lightweight Edge runtime).
Scalability Considerations:
- Edge Functions (Middleware, API Routes deployed to Edge) are highly scalable due to their distributed nature and serverless architecture.
- Design API routes to be stateless for better scalability.
4. Handling Images and Assets
next/imageComponent: (As noted from the Medium article snippet)- Purpose: Automatic image optimization (resizing, optimizing for different devices, modern formats like WebP).
- Features: Lazy loading by default,
priorityprop for LCP images,fillprop for responsive images that fill their container,sizesprop for more control over image selection at different breakpoints. - Benefits: Improved performance, better Core Web Vitals, reduced bandwidth.
- Best Practice: Always use
next/imagefor local and remote images instead of the native<img>tag.
- Static Assets (
publicfolder):- Files in the
publicfolder (e.g.,public/favicon.ico) are served from the root (/favicon.ico). - Use for favicons, robots.txt, static images not handled by
next/image(thoughnext/imageis preferred for images in components), etc.
- Files in the
- Fonts:
- Use
next/fontfor automatic font optimization (self-hosting, preloading, no layout shift). - Supports Google Fonts and local fonts.
- Use
5. Incremental Static Regeneration (ISR) and Caching Strategies
- ISR (Revalidation):
- Time-based revalidation:
export const revalidate = <seconds>;in a page file (App Router) orrevalidateprop ingetStaticProps(Pages Router). The page is re-generated in the background if a request comes in after the specified time. - On-demand revalidation: Use
revalidatePath()orrevalidateTag()(App Router) to manually trigger revalidation of specific paths or data tags, often after a CMS update or database change.
- Time-based revalidation:
- Caching Strategies (App Router):
- Next.js has a built-in caching mechanism that works with Server Components and data fetching.
- Data Cache:
fetchrequests are automatically cached by default. Control caching behavior with{ cache: 'force-cache' | 'no-store' }or{ next: { revalidate: <seconds> } }options infetch. - Full Route Cache: Statically rendered routes are cached at the edge. Dynamically rendered routes can also be cached.
- Router Cache (Client-side): Caches navigation payloads to make client-side transitions faster.
- Cache Tags: Use
fetch(URL, { next: { tags: ['collection'] } })to tag data fetches. Then userevalidateTag('collection')for granular on-demand revalidation.
- Best Practices for Caching & ISR:
- Identify appropriate revalidation times based on content volatility.
- Use on-demand ISR for instant updates when content changes in a headless CMS or database.
- Leverage cache tags for fine-grained control over data revalidation.
- Understand the different layers of caching in Next.js (Data Cache, Full Route Cache, Router Cache) to optimize effectively.
6. SEO Optimization for Dynamic Content
Next.js is inherently SEO-friendly due to its rendering capabilities.
- Metadata API (App Router):
- Use
generateMetadatafunction inlayout.jsorpage.jsto dynamically generate metadata (title, description, openGraph, etc.) based on route parameters or fetched data. - Static metadata can be exported as a
metadataobject. - File-based metadata:
favicon.ico,opengraph-image.jpg,robots.txt,sitemap.xml(can be static or dynamically generated viaroute.js).
- Use
- Server Rendering (SSR/SSG/ISR): Ensures search engine crawlers get fully rendered HTML content, which is crucial for indexing dynamic content.
- Sitemaps: Generate dynamic sitemaps (e.g., using a
sitemap.jsorsitemap.tsfile in theappdirectory that exports a default function) to help search engines discover all your pages. robots.txt: Control crawler access to your site.- Structured Data (JSON-LD): Include structured data in your pages to provide more context to search engines and enable rich snippets.
- Page Speed: Optimize for Core Web Vitals using
next/image,next/font, code splitting, and efficient data fetching. - Clean URLs: Next.js file-system routing naturally creates clean, readable URLs.
This summary provides a good foundation for the “Best Practices in Writing Next.js Applications” section of the report.
Best Practices for Writing Express.js Backends: Ensuring Robustness and Security
Express.js remains a highly popular and versatile Node.js framework for building backend APIs. Its minimalist nature provides flexibility, but this also means that establishing and adhering to best practices is crucial for developing scalable, maintainable, and secure applications. This section outlines key guidelines for structuring Express.js projects, leveraging TypeScript, designing secure APIs, handling errors and logs effectively, and integrating with frontends and databases.
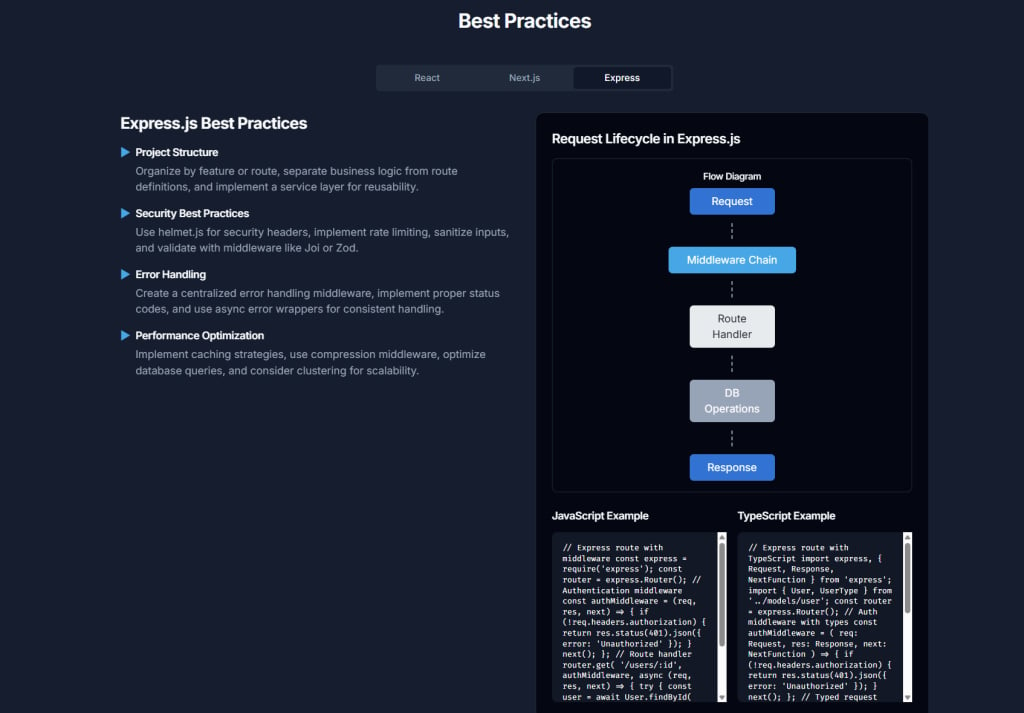
Project Structure and Modularization: Organizing for Growth
A well-defined project structure is the bedrock of a scalable Express.js application. It promotes separation of concerns, making the codebase easier to understand, navigate, and maintain as it grows.
A common and effective structure involves organizing files and folders by their responsibility:
src/config/: Contains configuration files, such as database connection details, environment variable loading (e.g., usingdotenv), and settings for external services.src/controllers/: Houses request handlers. Controllers are responsible for receiving incoming requests, validating them (often with the help of middleware), interacting with services to perform business logic, and sending responses back to the client.src/services/: Contains the core business logic of the application. Services abstract the interaction with data layers (models/repositories) and external APIs, keeping controllers lean and focused on request/response handling.src/models/: Defines database schemas and models if an ORM/ODM (like Mongoose for MongoDB, or Sequelize/Prisma for SQL databases) is used. This layer is responsible for data representation and interaction with the database.src/routes/: Defines the API routes and maps HTTP methods and URL endpoints to specific controller functions. Each major resource or feature often gets its own route file for better organization.src/middlewares/: Stores custom middleware functions. This can include middleware for authentication, authorization, input validation, logging, error handling, and more.src/utils/: A place for utility functions, helper classes, constants, or any other reusable code snippets that don’t fit neatly into other categories.src/app.ts(orapp.js): The main Express application setup file. This is where middleware is registered, routes are mounted, and the Express app instance is configured and exported.src/server.ts(orserver.js): Responsible for initializing and starting the HTTP server, listening on a specified port.
This modular approach ensures that different aspects of the application are decoupled, facilitating easier testing, debugging, and parallel development by team members.
Using TypeScript with Express: Enhancing Code Quality
Adopting TypeScript for Express.js development brings significant advantages, especially for scalable projects:
- Static Typing: Catches type-related errors at compile time rather than runtime, reducing bugs and improving code reliability.
- Improved Code Readability and Maintainability: Explicit types make the code easier to understand and reason about, especially for complex logic and data structures.
- Enhanced Developer Experience: Provides better autocompletion, refactoring capabilities, and navigation in IDEs.
Key practices for using TypeScript with Express include:
- Defining interfaces or types for request bodies (
req.body), query parameters (req.query), URL parameters (req.params), and API responses. This ensures type safety throughout the request-response lifecycle. - Leveraging TypeScript with ORMs/ODMs like TypeORM, Prisma, or Mongoose (with its type support) for type-safe database interactions.
- Using decorators for routes and dependency injection (with libraries like
routing-controllersorInversifyJS/tsyringe) can further enhance structure and testability in larger applications, though this is an optional architectural choice.
Secure API Design: Protecting Your Application and Users
Security is a non-negotiable aspect of backend development. Express.js applications must be fortified against common web vulnerabilities.
- Input Validation and Sanitization: Never trust user input. Rigorously validate all incoming data from request bodies, query parameters, URL parameters, and headers against expected schemas. Libraries like
express-validator,joi, orzodare excellent for this. Sanitize data before storing it or using it in queries if it’s not handled by an ORM’s built-in protections. - Authentication and Authorization: Implement robust authentication to verify user identities. JSON Web Tokens (JWT) are a common stateless authentication mechanism for APIs. Use libraries like
jsonwebtokenfor token management andpassport-jwtfor integrating with Passport.js. Once authenticated, enforce authorization (e.g., Role-Based Access Control – RBAC) to ensure users can only access resources and perform actions they are permitted to. - Rate Limiting: Protect your API from brute-force attacks and denial-of-service (DoS) attempts by implementing rate limiting. Middleware like
express-rate-limitcan restrict the number of requests a client can make within a specific time window. - HTTPS (TLS): Always use HTTPS in production to encrypt data in transit. This is typically handled by a reverse proxy like Nginx or a load balancer in front of your Express application.
- Helmet Middleware: Use the
helmetmiddleware (app.use(helmet());) to set various security-related HTTP headers. These headers help protect against common attacks like Cross-Site Scripting (XSS), clickjacking, and others by instructing the browser to enforce certain security policies. - CORS (Cross-Origin Resource Sharing): If your API is intended to be accessed from different domains (e.g., a frontend application running on a separate domain), configure CORS using the
corsmiddleware. Be as specific as possible with allowed origins in production environments rather than using a wildcard (*). - Preventing SQL Injection: If using SQL databases, always use an ORM/ODM that handles query sanitization (like Sequelize or Prisma) or use parameterized queries/prepared statements. Never construct SQL queries by directly concatenating user input.
- Dependency Management: Regularly scan your project dependencies for known vulnerabilities using tools like
npm audit, Snyk, or GitHub Dependabot. Keep your dependencies up to date. - Disable
X-Powered-ByHeader: Reduce server fingerprinting by disabling theX-Powered-By: Expressheader usingapp.disable('x-powered-by');(Helmet often handles this by default).
Error Handling and Logging: Ensuring Stability and Insight
Robust error handling and comprehensive logging are crucial for maintaining application stability and diagnosing issues in production.
- Centralized Error Handling Middleware: Implement a dedicated error-handling middleware function that is defined last in your middleware stack. This middleware should catch all errors passed via
next(error). It should standardize error responses (e.g., sending a JSON response with an appropriate HTTP status code and error message) and avoid leaking sensitive details like stack traces to the client in production. - Asynchronous Error Handling: Ensure that errors occurring in asynchronous operations (e.g., within
async/awaitfunctions or Promise chains in your route handlers and services) are correctly caught and passed to the centralized error handler usingnext(error). Libraries likeexpress-async-errorscan simplify this by automatically wrapping route handlers. - Comprehensive Logging: Implement structured logging for requests, errors, and significant application events. Use mature logging libraries like
winstonorpino, which offer features like log levels, custom formatting, and multiple transport options (e.g., logging to console, files, or external logging services like ELK Stack, Splunk, or Datadog). Include contextual information in logs, such as timestamps, request IDs, user IDs (if applicable), and relevant error details. - HTTP Request Logging: Use middleware like
morganfor logging incoming HTTP requests. This is invaluable for debugging and monitoring traffic patterns.
Middleware Usage: Enhancing Functionality
Middleware functions are fundamental to Express.js, allowing you to execute code during the request-response cycle.
- Common Built-in and Third-Party Middleware:
express.json(): For parsing JSON request bodies.express.urlencoded({ extended: true }): For parsing URL-encoded request bodies.cors: For enabling CORS.helmet: For security headers.morgan: For HTTP request logging.
- Custom Middleware: Write custom middleware for application-specific concerns like authentication checks, authorization logic, advanced validation, or request enrichment.
- Best Practices: Keep middleware functions small, focused, and well-ordered, as they execute sequentially. Leverage well-maintained third-party middleware for common tasks, and create custom middleware for unique application requirements.
Integration with Frontend and Databases: Connecting the Stack
- Frontend Communication: Express.js backends typically expose RESTful APIs that serve JSON data to frontend applications. GraphQL, implemented with libraries like
apollo-server-express, is also a viable alternative for more complex data requirements. - Database Integration: Choose a database that suits your application’s needs (e.g., PostgreSQL, MySQL, MongoDB). Use an ORM (like Sequelize, Prisma) or ODM (like Mongoose) to interact with the database in a structured and often type-safe manner. This abstracts raw database queries, provides a model layer, and can help with tasks like migrations and data validation. Ensure database connection pooling is used for efficient resource management, and always store database credentials securely using environment variables.
By following these best practices, developers can build Express.js backends that are not only powerful and flexible but also secure, scalable, and maintainable, forming a solid foundation for modern full-stack applications.
Best Practices for Writing Express.js Backends: Ensuring Robustness and Security
Express.js remains a highly popular and versatile Node.js framework for building backend APIs. Its minimalist nature provides flexibility, but this also means that establishing and adhering to best practices is crucial for developing scalable, maintainable, and secure applications. This section outlines key guidelines for structuring Express.js projects, leveraging TypeScript, designing secure APIs, handling errors and logs effectively, and integrating with frontends and databases.
Project Structure and Modularization: Organizing for Growth
A well-defined project structure is the bedrock of a scalable Express.js application. It promotes separation of concerns, making the codebase easier to understand, navigate, and maintain as it grows.
A common and effective structure involves organizing files and folders by their responsibility:
src/config/: Contains configuration files, such as database connection details, environment variable loading (e.g., usingdotenv), and settings for external services.src/controllers/: Houses request handlers. Controllers are responsible for receiving incoming requests, validating them (often with the help of middleware), interacting with services to perform business logic, and sending responses back to the client.src/services/: Contains the core business logic of the application. Services abstract the interaction with data layers (models/repositories) and external APIs, keeping controllers lean and focused on request/response handling.src/models/: Defines database schemas and models if an ORM/ODM (like Mongoose for MongoDB, or Sequelize/Prisma for SQL databases) is used. This layer is responsible for data representation and interaction with the database.src/routes/: Defines the API routes and maps HTTP methods and URL endpoints to specific controller functions. Each major resource or feature often gets its own route file for better organization.src/middlewares/: Stores custom middleware functions. This can include middleware for authentication, authorization, input validation, logging, error handling, and more.src/utils/: A place for utility functions, helper classes, constants, or any other reusable code snippets that don’t fit neatly into other categories.src/app.ts(orapp.js): The main Express application setup file. This is where middleware is registered, routes are mounted, and the Express app instance is configured and exported.src/server.ts(orserver.js): Responsible for initializing and starting the HTTP server, listening on a specified port.
This modular approach ensures that different aspects of the application are decoupled, facilitating easier testing, debugging, and parallel development by team members.
Using TypeScript with Express: Enhancing Code Quality
Adopting TypeScript for Express.js development brings significant advantages, especially for scalable projects:
- Static Typing: Catches type-related errors at compile time rather than runtime, reducing bugs and improving code reliability.
- Improved Code Readability and Maintainability: Explicit types make the code easier to understand and reason about, especially for complex logic and data structures.
- Enhanced Developer Experience: Provides better autocompletion, refactoring capabilities, and navigation in IDEs.
Key practices for using TypeScript with Express include:
- Defining interfaces or types for request bodies (
req.body), query parameters (req.query), URL parameters (req.params), and API responses. This ensures type safety throughout the request-response lifecycle. - Leveraging TypeScript with ORMs/ODMs like TypeORM, Prisma, or Mongoose (with its type support) for type-safe database interactions.
- Using decorators for routes and dependency injection (with libraries like
routing-controllersorInversifyJS/tsyringe) can further enhance structure and testability in larger applications, though this is an optional architectural choice.
Secure API Design: Protecting Your Application and Users
Security is a non-negotiable aspect of backend development. Express.js applications must be fortified against common web vulnerabilities.
- Input Validation and Sanitization: Never trust user input. Rigorously validate all incoming data from request bodies, query parameters, URL parameters, and headers against expected schemas. Libraries like
express-validator,joi, orzodare excellent for this. Sanitize data before storing it or using it in queries if it’s not handled by an ORM’s built-in protections. - Authentication and Authorization: Implement robust authentication to verify user identities. JSON Web Tokens (JWT) are a common stateless authentication mechanism for APIs. Use libraries like
jsonwebtokenfor token management andpassport-jwtfor integrating with Passport.js. Once authenticated, enforce authorization (e.g., Role-Based Access Control – RBAC) to ensure users can only access resources and perform actions they are permitted to. - Rate Limiting: Protect your API from brute-force attacks and denial-of-service (DoS) attempts by implementing rate limiting. Middleware like
express-rate-limitcan restrict the number of requests a client can make within a specific time window. - HTTPS (TLS): Always use HTTPS in production to encrypt data in transit. This is typically handled by a reverse proxy like Nginx or a load balancer in front of your Express application.
- Helmet Middleware: Use the
helmetmiddleware (app.use(helmet());) to set various security-related HTTP headers. These headers help protect against common attacks like Cross-Site Scripting (XSS), clickjacking, and others by instructing the browser to enforce certain security policies. - CORS (Cross-Origin Resource Sharing): If your API is intended to be accessed from different domains (e.g., a frontend application running on a separate domain), configure CORS using the
corsmiddleware. Be as specific as possible with allowed origins in production environments rather than using a wildcard (*). - Preventing SQL Injection: If using SQL databases, always use an ORM/ODM that handles query sanitization (like Sequelize or Prisma) or use parameterized queries/prepared statements. Never construct SQL queries by directly concatenating user input.
- Dependency Management: Regularly scan your project dependencies for known vulnerabilities using tools like
npm audit, Snyk, or GitHub Dependabot. Keep your dependencies up to date. - Disable
X-Powered-ByHeader: Reduce server fingerprinting by disabling theX-Powered-By: Expressheader usingapp.disable('x-powered-by');(Helmet often handles this by default).
Error Handling and Logging: Ensuring Stability and Insight
Robust error handling and comprehensive logging are crucial for maintaining application stability and diagnosing issues in production.
- Centralized Error Handling Middleware: Implement a dedicated error-handling middleware function that is defined last in your middleware stack. This middleware should catch all errors passed via
next(error). It should standardize error responses (e.g., sending a JSON response with an appropriate HTTP status code and error message) and avoid leaking sensitive details like stack traces to the client in production. - Asynchronous Error Handling: Ensure that errors occurring in asynchronous operations (e.g., within
async/awaitfunctions or Promise chains in your route handlers and services) are correctly caught and passed to the centralized error handler usingnext(error). Libraries likeexpress-async-errorscan simplify this by automatically wrapping route handlers. - Comprehensive Logging: Implement structured logging for requests, errors, and significant application events. Use mature logging libraries like
winstonorpino, which offer features like log levels, custom formatting, and multiple transport options (e.g., logging to console, files, or external logging services like ELK Stack, Splunk, or Datadog). Include contextual information in logs, such as timestamps, request IDs, user IDs (if applicable), and relevant error details. - HTTP Request Logging: Use middleware like
morganfor logging incoming HTTP requests. This is invaluable for debugging and monitoring traffic patterns.
Middleware Usage: Enhancing Functionality
Middleware functions are fundamental to Express.js, allowing you to execute code during the request-response cycle.
- Common Built-in and Third-Party Middleware:
express.json(): For parsing JSON request bodies.express.urlencoded({ extended: true }): For parsing URL-encoded request bodies.cors: For enabling CORS.helmet: For security headers.morgan: For HTTP request logging.
- Custom Middleware: Write custom middleware for application-specific concerns like authentication checks, authorization logic, advanced validation, or request enrichment.
- Best Practices: Keep middleware functions small, focused, and well-ordered, as they execute sequentially. Leverage well-maintained third-party middleware for common tasks, and create custom middleware for unique application requirements.
Integration with Frontend and Databases: Connecting the Stack
- Frontend Communication: Express.js backends typically expose RESTful APIs that serve JSON data to frontend applications. GraphQL, implemented with libraries like
apollo-server-express, is also a viable alternative for more complex data requirements. - Database Integration: Choose a database that suits your application’s needs (e.g., PostgreSQL, MySQL, MongoDB). Use an ORM (like Sequelize, Prisma) or ODM (like Mongoose) to interact with the database in a structured and often type-safe manner. This abstracts raw database queries, provides a model layer, and can help with tasks like migrations and data validation. Ensure database connection pooling is used for efficient resource management, and always store database credentials securely using environment variables.
By following these best practices, developers can build Express.js backends that are not only powerful and flexible but also secure, scalable, and maintainable, forming a solid foundation for modern full-stack applications.
AI Tools for Development Acceleration (Cursor & Supabase)
Sources:
- Supabase Docs – AI Prompts: https://supabase.com/docs/guides/getting-started/ai-prompts (accessed May 15, 2025)
- Cursor Website: https://www.cursor.com/ (accessed May 15, 2025)
- YouTube – 10x Faster Development: Cursor.com Composer Mode + Supabase Types | AI-Assisted Coding: https://www.youtube.com/watch?v=69XqOWGOnUw (accessed May 15, 2025)
- Web Search Results (various for ethical considerations and general AI tool capabilities)
1. Overview of Cursor as an AI Code Assistant
Cursor is an AI-powered code editor designed to accelerate software development. It is built on top of VS Code, allowing developers to use their existing extensions, themes, and keybindings.
Key Capabilities:
- Natural Language Editing/Generation:
- Write code using instructions (prompts).
- Update entire classes or functions with a simple prompt.
- Generate new code blocks based on descriptions.
- Codebase Awareness (“Knows your codebase”):
- Can be pointed to specific files or documentation to understand context.
- Helps in getting answers from the codebase.
- Can refer to files or docs when generating or modifying code.
- Autocompletion:
- Predicts the next edit or completes code snippets.
- Fast and intelligent autocompletion.
- Code Refactoring:
- Assist in refactoring existing code based on prompts or selected code blocks.
- Inline Explanations/Chat with Code:
- Ask questions about selected code directly in the editor.
- Get explanations of complex code segments.
- Debugging Assistance:
- Can help identify and suggest fixes for bugs.
- Frontier Intelligence:
- Powered by a mix of purpose-built and frontier AI models (e.g., GPT-4, Claude).
- Familiar Environment:
- Based on VS Code, so it feels familiar to many developers.
- Supports importing existing VS Code extensions, themes, and keybindings.
- Privacy Options:
- Offers a “Privacy Mode” where code is not stored remotely.
- SOC 2 certified, indicating a commitment to security and privacy.
- Composer Mode (as seen in YouTube video):
- A specific mode for AI-assisted coding, allowing for more interactive and iterative code generation and modification.
2. Integrating Supabase in Full-Stack Apps using AI-Generated Code (with Cursor)
Supabase is an open-source Firebase alternative that provides a suite of tools for building backends, including a Postgres database, authentication, instant APIs, edge functions, real-time subscriptions, and storage.
How AI (Cursor) can help with Supabase:
- Generating Supabase Queries:
- AI can generate SQL queries for Supabase based on natural language descriptions.
- Can help create queries for fetching, inserting, updating, or deleting data from Supabase tables.
- Scaffolding Components that Interact with Supabase:
- Generate frontend components (e.g., React, Next.js) that fetch data from or send data to Supabase APIs.
- Create backend API routes (e.g., in Next.js or Express.js) that use the Supabase client library.
- Writing Supabase Edge Functions:
- Supabase provides prompts for writing Edge Functions.
- AI can help scaffold the basic structure of an Edge Function, implement business logic, and handle requests/responses.
- Database Schema and Migrations:
- Supabase provides prompts for declarative database schema, creating RLS policies, database functions, and migrations.
- AI can assist in translating requirements into SQL DDL statements or migration scripts compatible with Supabase.
- Authentication Setup:
- Supabase provides prompts for bootstrapping a Next.js app with Supabase Auth.
- AI can help generate the necessary code for user sign-up, sign-in, sign-out, and session management using Supabase Auth.
- Leveraging Supabase Types (as seen in YouTube video with Cursor):
- Supabase can generate TypeScript types from your database schema (
supabase gen types --lang typescript --local). - Providing these types to Cursor (e.g., by including the types file in the context) makes AI suggestions significantly smarter and more accurate.
- The AI understands the exact database schema, leading to type-safe suggestions in composer mode and intelligent autocomplete.
- Reduces back-and-forth with the AI as it has better context.
- Supabase can generate TypeScript types from your database schema (
3. Prompts Developers Can Use Inside Cursor (for Supabase & General Backend)
Supabase itself provides curated prompts for use with AI tools like Cursor. These can be copied to a file in the repo and included as “project rules” in Cursor.
Examples of Prompts (Conceptual – specific prompts are in Supabase docs):
- Scaffolding Components:
- “Create a React component that fetches and displays a list of products from the Supabase ‘products’ table. Include columns: name, price, description.”
- “Generate a Next.js API route at ‘/api/users’ that uses the Supabase client to retrieve all users from the ‘users’ table.”
- Generating Supabase Queries/Client Code:
- “Write a Supabase JavaScript query to select all users older than 30 from the ‘profiles’ table.”
- “Generate code to insert a new record into the ‘orders’ table in Supabase with the following data: {user_id: ‘…’, product_id: ‘…’, quantity: …}. Handle potential errors.”
- (With Supabase types provided) “Using the Supabase client and the generated types, create a function to fetch a user profile by ID, ensuring type safety.”
- Debugging and Explaining Backend Code (Express.js example):
- (Select a block of Express.js middleware) “Explain what this middleware does and identify any potential security vulnerabilities.”
- (With an error message from an Express.js backend) “This error occurred in my Express.js route handler: [paste error]. Here is the relevant code: [paste code]. What is the likely cause and how can I fix it?”
- “Refactor this Express.js controller to use async/await and improve error handling.”
- Writing Supabase Edge Functions:
- “Create a Supabase Edge Function that takes a user ID as input, queries the ‘user_permissions’ table, and returns a list of permissions for that user.”
- Creating RLS Policies:
- “Generate an RLS policy for the ‘documents’ table in Supabase that allows users to only select documents they own (where ‘documents.owner_id’ matches the authenticated user’s ID).”
4. Ethical Considerations When Using AI to Generate Code
- Bias in AI Models:
- AI models are trained on vast amounts of code, which may contain biases.
- Generated code could reflect these biases, leading to unfair or discriminatory outcomes if not carefully reviewed.
- Security Vulnerabilities:
- AI-generated code might inadvertently introduce security flaws if the training data included vulnerable patterns or if the AI doesn’t fully understand security best practices.
- Over-reliance on AI without proper security reviews can be risky.
- Code Ownership and Licensing:
- AI models learn from existing code, including open-source projects with various licenses.
- There can be ambiguity regarding the ownership of AI-generated code and potential licensing conflicts if the AI reproduces code snippets from licensed sources without proper attribution.
- Developers need to be aware of the provenance of generated code.
- Quality and Maintainability:
- AI might generate code that works but is poorly structured, inefficient, or difficult to maintain.
- It may not always follow best practices or project-specific coding standards.
- Over-Reliance and Skill Degradation:
- Excessive reliance on AI for code generation could potentially hinder the development of problem-solving skills and deep understanding among developers, especially junior ones.
- Transparency and Explainability:
- It can be difficult to understand why an AI generated a particular piece of code, making debugging or modification challenging if the developer doesn’t fully grasp the logic.
- Data Privacy:
- When using AI tools, especially cloud-based ones, developers must be mindful of the code and data being sent to the AI service. Cursor offers a “Privacy Mode” to address this, but it’s a general concern for AI coding tools.
5. Tips for Developers to Validate and Refactor AI-Generated Code
- Treat AI as a Co-Pilot, Not an Autopilot:
- Always critically review AI-generated code. You are ultimately responsible for the code in your project.
- Understand the Generated Code:
- Don’t blindly accept suggestions. Ensure you understand what the code does, why it was generated that way, and how it fits into your application.
- Use the AI’s explanation features if available.
- Thorough Testing:
- Write unit tests, integration tests, and end-to-end tests for any functionality involving AI-generated code.
- Test edge cases and error conditions specifically.
- Security Review:
- Manually inspect for common security vulnerabilities (e.g., injection flaws, XSS, insecure direct object references).
- Use static analysis security testing (SAST) tools.
- Performance Testing:
- Assess the performance implications of the generated code, especially for critical paths or data-intensive operations.
- Adherence to Coding Standards and Best Practices:
- Refactor the code to ensure it aligns with your project’s coding standards, style guides, and architectural patterns.
- Improve readability, maintainability, and efficiency if needed.
- Incremental Integration:
- Integrate AI-generated code in small, manageable chunks rather than large, complex blocks.
- Check for Licensing Issues:
- Be cautious if the generated code looks very similar to existing libraries or snippets. Ensure no licensing terms are violated.
- Use Strong Typing (e.g., with Supabase types in Cursor):
- Providing strong type information to the AI can significantly improve the quality and correctness of generated code, reducing the validation burden.
- Iterate with the AI:
- If the initial generation isn’t perfect, provide feedback and ask the AI to refine its suggestions. This is a key strength of tools like Cursor.
This research provides a foundational understanding of how Cursor and Supabase can be used with AI to accelerate development, along with important considerations for developers.