Building AI features into your SaaS product? Your LLM API bills could range from $50/month to $50,000/month depending on one critical decision: which model you choose and how you use it.
Here’s what most developers miss: GPT-5.4 costs $2.50 per million input tokens, while DeepSeek V3.2 charges just $0.14 for the same work. That’s an 18x price difference. For a production app processing 10M tokens monthly, you’re looking at $25 versus $1.40.
This guide breaks down exact 2026 pricing from OpenAI, Anthropic, Google, and DeepSeek, then shows you five optimization strategies that cut real-world costs by 47-80% without degrading user experience.

LLM API Pricing Comparison 2026
Let’s start with the raw numbers. All prices below are per 1 million tokens as of April 2026:
| Model | Input Price | Output Price | Context Window | Best For |
|---|---|---|---|---|
| DeepSeek V3.2 | $0.14 | $0.28 | 128K | High-volume simple tasks |
| Claude Haiku 4.5 | $0.25 | $1.25 | 200K | Fast responses, classification |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | Long context, multimodal |
| GPT-4o-mini | $0.15 | $0.60 | 128K | General purpose, cheap |
| Gemini 2.5 Pro | $1.25 | $10.00 | 2M | Complex reasoning, long docs |
| GPT-5.4 | $2.50 | $7.50 | 128K | Balanced performance/cost |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K | Writing, code, analysis |
| Claude Opus 4.6 | $5.00 | $25.00 | 200K | Complex reasoning, agents |
| GPT-5 | $10.00 | $30.00 | 128K | Maximum capability tasks |
Key Pricing Insights
- DeepSeek V3.2 is the budget king — At $0.14/$0.28 per million tokens, it’s 18x cheaper than GPT-5 for input and 107x cheaper for output. Quality benchmarks show it competes with mid-tier models from OpenAI and Anthropic.
- Claude Haiku 4.5 punches above its weight — Anthropic’s fastest model costs less than Gemini Flash and delivers strong performance on classification and simple Q&A tasks.
- Output tokens cost 3-5x more than input — This matters for chatbots and agents that generate long responses. Optimizing prompt length only gets you so far.
- Context window size affects total cost — Gemini 2.5 Pro’s 2M context window means you can process entire codebases or legal documents in one call, but at $1.25/M input, a full 2M context run costs $2.50 per call.
Real-World Cost Scenarios
Let’s translate these prices into actual monthly bills for common SaaS use cases:
| Use Case | Monthly Tokens | GPT-5.4 Cost | Claude Sonnet Cost | DeepSeek V3.2 Cost |
|---|---|---|---|---|
| Support chatbot (500 conversations/day) | 5M | $50 | $90 | $2.10 |
| Code review assistant | 15M | $150 | $270 | $6.30 |
| AI agent (200 sessions, growing context) | 50M | $500 | $900 | $21.00 |
| Document analysis platform | 100M | $1,000 | $1,800 | $42.00 |
| High-volume content generation | 500M | $5,000 | $9,000 | $210.00 |
For a bootstrapped SaaS, that’s the difference between profitable and burning cash. Even well-funded startups should care — I’ve seen teams waste $20K/month on overprovisioned models before optimizing.

5 Strategies to Cut LLM Costs 47-80%
Raw pricing is only half the story. How you use these models matters more. Here are five proven optimization strategies with real savings data:
1. Model Routing (40-70% Savings)
Not every request needs GPT-5. Route simple tasks to cheaper models and reserve expensive ones for complex work:
def route_request(request):
# Simple classification tasks
if request.task_type == "classify":
return "gpt-4o-mini" # $0.15/M vs $2.50/M
# Long context needs
if request.token_count > 100000:
return "gemini-2.5-pro" # 2M context, $1.25/M
# Complex reasoning
if request.complexity_score > 0.8:
return "claude-opus-4.6" # $5/M, worth it for hard problems
# Tool-heavy workflows
if request.requires_tools:
return "gpt-5.4" # Best tool calling
# Default to cost-effective
return "gpt-4o-mini"Real impact: A customer support bot routing 80% of queries to GPT-4o-mini and 20% to GPT-5.4 cut costs by 62% while maintaining quality scores.
2. Prompt Caching (45-80% Reduction)
Both OpenAI and Anthropic offer prompt caching for repeated system prompts and long context. Cached tokens cost dramatically less:
| Provider | Standard Input | Cached Input | Savings |
|---|---|---|---|
| Anthropic Claude | $5.00/M | $0.50/M (Opus) | 90% |
| OpenAI GPT | $2.50/M | $0.625/M (GPT-5.4) | 75% |
How to enable caching:
# Anthropic - automatic caching for repeated prefixes
client.messages.create(
model="claude-opus-4-6-20260319",
messages=[{"role": "user", "content": large_document}],
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"}
)
# OpenAI - cache_control in messages
client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": system_prompt,
"cache_control": {"type": "ephemeral"}}
]
)Real impact: Claude Code sessions with caching cost ~$0.34 versus $2+ without. For high-volume apps with repeated prompts, expect 45-80% cost reduction.
3. Context Compaction (50-70% Token Reduction)
Long conversations accumulate context fast. Instead of sending the full history every turn, compact old messages:
def compact_context(messages, max_tokens=50000):
current_tokens = count_tokens(messages)
if current_tokens < max_tokens:
return messages
# Keep last 5 messages, summarize the rest
recent = messages[-5:]
old = messages[:-5]
summary = llm.generate("Summarize this conversation:", old)
return [
{"role": "system", "content": f"Previous conversation summary: {summary}"},
*recent
]Real impact: A 200K-token conversation compacted to 80K tokens saves 60% on input costs for that turn and every subsequent turn. For a Claude Opus session, that’s $0.60 saved per turn.
4. Semantic Caching (Up to 73% Savings)
For repeated or similar queries, cache the response entirely. Semantic caching uses embeddings to match similar questions:
import redis
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
redis_client = redis.Redis(host='localhost', port=6379)
def semantic_cache(query, generate_fn, threshold=0.85):
query_embedding = model.encode(query)
# Search for similar cached queries
similar = redis_client.execute_command(
'FT.SEARCH', 'idx:queries', '*=>[KNN 1 @embedding $vec AS score]',
'PARAMS', '2', 'vec', query_embedding.tobytes(),
'FILTER', 'score >= $threshold',
'PARAMS', '2', 'threshold', threshold
)
if similar:
return redis_client.get(f'cache:{similar[0]}')
# Generate and cache
response = generate_fn(query)
redis_client.set(f'cache:{query_id}', response)
redis_client.execute_command('HSET', f'idx:queries', query_id,
'embedding', query_embedding.tobytes())
return responseReal impact: Production teams with high query repetition report 73% cost reduction using Redis-based semantic caching. Support bots see the highest hit rates (40-60% of queries are repeats).
5. Batch Processing (50% Discount)
OpenAI’s batch API offers 50% discounts for async workloads that don’t need real-time responses:
# Instead of 100 individual calls:
for doc in documents:
response = client.chat.completions.create(...) # Full price
# Use batch API:
batch_input = []
for doc in documents:
batch_input.append({{
"custom_id": doc.id,
"method": "POST",
"url": "/v1/chat/completions",
"body": {{"model": "gpt-5.4", "messages": doc.messages}}
}})
batch_file = client.files.create(
file=json.dumps(batch_input).encode(),
purpose="batch"
)
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
# 50% cheaper, results in 24 hoursBest for: Document processing, content generation, data enrichment — anything that can wait hours for results.
Model Selection Framework
Use this decision tree to pick the right model for your use case:
- Budget under $100/month? → DeepSeek V3.2 or GPT-4o-mini
- Need 100K+ context? → Gemini 2.5 Pro (2M) or Claude Sonnet (200K)
- Building an AI agent? → Claude Opus 4.6 (best reasoning) with caching enabled
- High-volume simple tasks? → Claude Haiku 4.5 or Gemini Flash
- Code generation? → Claude Sonnet 4.5 or GPT-5.4
- Multimodal (images + text)? → Gemini 2.5 Pro or GPT-5.4
- Latency critical (<500ms)? → Claude Haiku 4.5 or GPT-4o-mini
Key Takeaways
- LLM pricing varies 100x+ between cheapest (DeepSeek V3.2 at $0.14/M) and most expensive (GPT-5 at $10/M input)
- Model routing alone can cut costs 40-70% by matching task complexity to model tier
- Prompt caching delivers 45-80% savings for repeated system prompts and long contexts
- Semantic caching eliminates redundant API calls for similar queries (73% reduction reported)
- Context compaction reduces token counts 50-70% in long conversations
- Batch processing offers 50% discounts for non-real-time workloads
- Combined, these strategies can reduce production LLM costs by 47-80% without quality loss
FAQ
What is the cheapest LLM API in 2026?
DeepSeek V3.2 is the cheapest high-quality option at $0.14 per million input tokens and $0.28 per million output tokens. That’s 18x cheaper than GPT-5.4 for input and 107x cheaper for output. For comparison, processing 10M tokens costs $2.10 with DeepSeek versus $50 with GPT-5.4.
How much does Claude API cost?
Anthropic’s Claude API pricing (April 2026): Claude Opus 4.6 costs $5/M input and $25/M output. Claude Sonnet 4.5 is $3/M input and $15/M output. Claude Haiku 4.5 is the budget option at $0.25/M input and $1.25/M output. Cached input tokens cost 90% less ($0.50/M for Opus).
Is GPT-5 worth the extra cost?
GPT-5 costs $10/M input and $30/M output — 4x more than GPT-5.4 ($2.50/$7.50) and 7x more than Claude Sonnet 4.5 ($3/$15). It’s worth it for: complex reasoning tasks, multi-step tool use, or when you need maximum capability. For 80% of SaaS use cases (chatbots, content generation, simple Q&A), GPT-5.4 or Claude Sonnet deliver equivalent results at a fraction of the cost.
How do I reduce my LLM API costs?
Five proven strategies: (1) Model routing — send simple tasks to cheaper models (40-70% savings). (2) Prompt caching — cache repeated system prompts (45-80% reduction). (3) Context compaction — summarize old conversation turns (50-70% token reduction). (4) Semantic caching — cache similar queries with embeddings (up to 73% savings). (5) Batch processing — use async batch API for non-real-time work (50% discount).
What is the best LLM for coding in 2026?
Claude Sonnet 4.5 ($3/M input, $15/M output) is the best balance of coding capability and cost. It outperforms GPT-5.4 on code generation benchmarks while costing similar prices. For budget-conscious teams, DeepSeek V3.2 ($0.14/$0.28) delivers surprisingly strong coding performance at 20x lower cost. For complex refactoring across large codebases, Claude Opus 4.6 ($5/$25) provides the deepest reasoning.
Conclusion
LLM pricing in 2026 ranges from dirt cheap (DeepSeek at $0.14/M) to premium (GPT-5 at $10/M). The key is matching model capability to task complexity and applying optimization strategies like caching, routing, and compaction.
Start with efficient models like GPT-4o-mini or Claude Haiku for everything. Upgrade only when benchmarks or user feedback show you need more capability. Enable caching from day one. Your future self — and your CFO — will thank you.
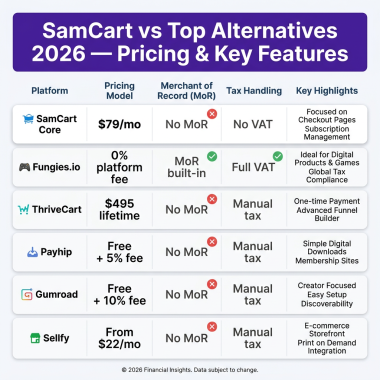
Ready to optimize your payment infrastructure? Get started with Fungies — handle payments, VAT, and sales tax compliance automatically so you can focus on building great products.
References
- CostGoat — LLM API Pricing Comparison (April 2026)
- TLDL — LLM API Pricing 2026 Guide
- LLM Gateway — OpenAI vs Anthropic vs Google Cost Comparison
- Mavik Labs — LLM Cost Optimization in 2026
- Morph — LLM Cost Optimization: Cut API Spend by 70-90%
- Redis — LLMOps Guide 2026