Here’s a number that should get your attention: 120+ AI agent frameworks launched in the past 18 months, and every major AI lab now ships its own SDK. If you’re trying to pick a framework for your next project, the choice feels overwhelming.
But here’s what actually matters: after deploying agents across healthcare, fintech, and SaaS platforms, teams consistently report that framework choice depends on just three factors—your failure tolerance, observability requirements, and team’s ability to debug what goes wrong when an agent loops at 2 AM.
In this guide, I’ll walk you through the five frameworks that matter most in 2026, when to use each one, and how to evaluate them for your specific use case. No fluff. Just production-tested recommendations with real code examples.
What Is an AI Agent Framework (And Why You Need One)
An AI agent framework is the orchestration layer between your large language model and the real world. It handles tool calling, state management, error recovery, and multi-step reasoning. Without a framework, you’re writing custom glue code for every integration—and debugging becomes a nightmare when agents fail mid-task.
The frameworks that survived 2025’s hype cycle share four characteristics:
- State persistence — Agents can pause, resume, and recover from failures
- Tool orchestration — Clean abstractions for calling APIs, databases, and external services
- Observability — You can trace exactly what happened during an agent run
- Human-in-the-loop — Humans can review, approve, or redirect agent decisions
Frameworks lacking these features work fine in demos but break in production. I’ve seen teams waste months on frameworks that couldn’t handle basic error recovery.
The 5 AI Agent Frameworks That Matter in 2026
After analyzing production deployments, GitHub adoption metrics, and enterprise usage patterns, five frameworks stand out. Each serves a different use case, and choosing the wrong one will cost you velocity.
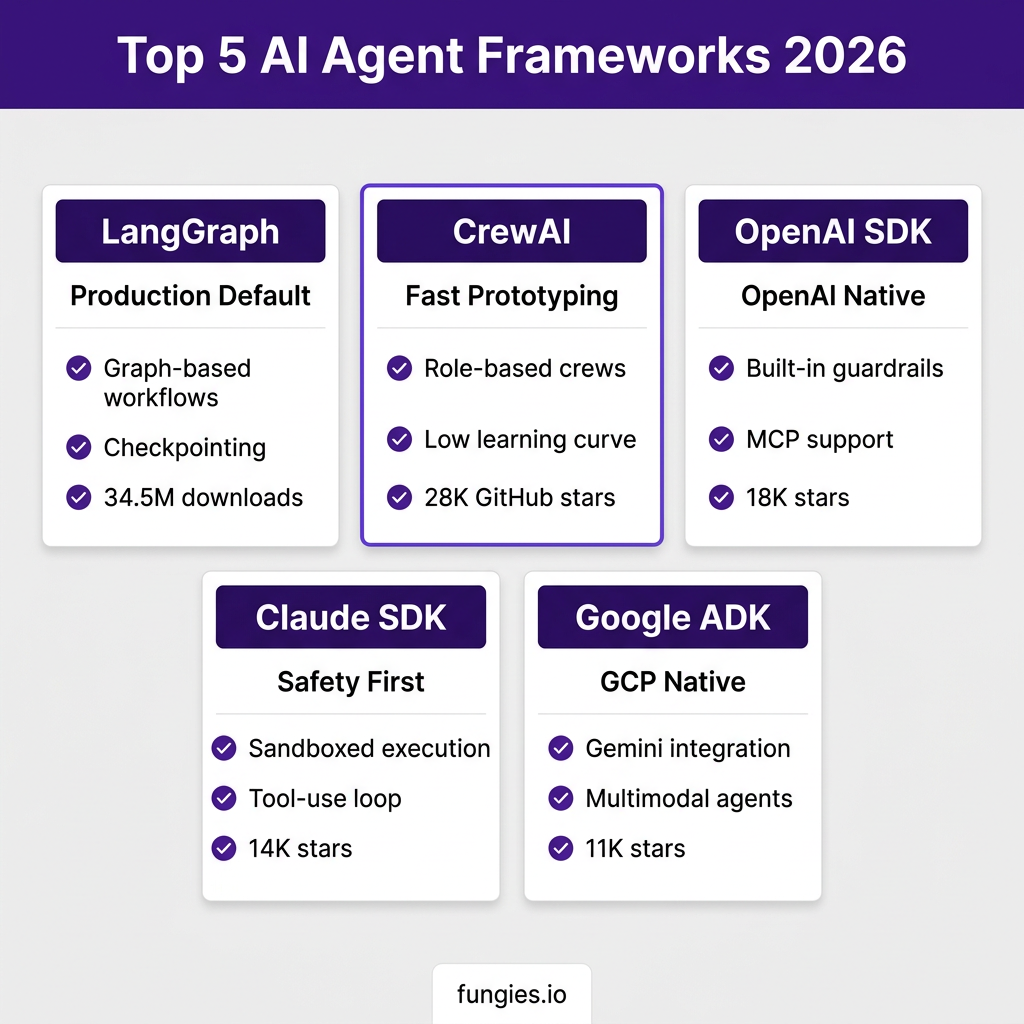
1. LangGraph — The Production Standard
LangGraph is LangChain’s graph-based orchestration layer, and it’s become the default choice for teams building complex, stateful agent workflows. With 34.5 million monthly downloads and deployments at Klarna, Cisco, and Vizient, it’s the most battle-tested framework available.
Why teams choose it:
- Directed graph architecture makes every state transition explicit and auditable
- Built-in checkpointing with time-travel debugging—you can replay any step
- Human-in-the-loop patterns are first-class, not bolted on
- LangSmith integration provides step-by-step observability
- Stateful patterns can reduce LLM calls by 40-50% on repeat requests
The trade-off: The learning curve is steep. You’ll need to think in graphs, which isn’t natural for everyone. A healthcare client I worked with saw accuracy jump from 71% to 93% after implementing context isolation at the graph node level—but it took three weeks to get there.
Best for: Complex, multi-step workflows requiring production reliability, audit trails, and compliance.
2. CrewAI — Fastest Path to Working Agents
CrewAI takes a different approach: role-based multi-agent crews. You define agents with specific roles (researcher, writer, reviewer), assign them tasks, and let the framework handle orchestration. With 28,000 GitHub stars and a low learning curve, it’s the fastest way to get a working prototype.
Why teams choose it:
- 2-4 hours from zero to working multi-agent system
- Role-based architecture matches how teams actually think about work
- No graph complexity—just define agents and tasks
- Strong community and extensive examples
The trade-off: Less control over execution flow. When things break, debugging is harder than LangGraph because the orchestration is more abstracted.
Best for: Rapid prototyping, content generation workflows, and teams new to agent development.
3. OpenAI Agents SDK — OpenAI-Native Production
OpenAI’s official SDK represents a maturation of their agent tooling. Released in early 2026, it provides handoff orchestration, built-in guardrails, and native MCP (Model Context Protocol) support. With 18,000 GitHub stars, it’s gaining traction among teams already committed to OpenAI’s ecosystem.
Why teams choose it:
- Native integration with OpenAI’s latest models (GPT-5, o3, o4)
- Built-in safety guardrails and content filtering
- First-class MCP support for tool integration
- Simpler than LangGraph for OpenAI-specific use cases
The trade-off: Model lock-in. If OpenAI changes pricing or you need to switch models, migration is harder than framework-agnostic alternatives.
Best for: Teams standardized on OpenAI who want production-ready agents without framework complexity.
4. Claude Agent SDK — Safety-First Autonomous Agents
Anthropic’s SDK emphasizes safety and sandboxed execution. It excels at autonomous tool-using agents with built-in protections against prompt injection and unintended actions. The 14,000 GitHub stars reflect its popularity among security-conscious teams.
Why teams choose it:
- Sandboxed execution environment for untrusted operations
- Strong protections against prompt injection attacks
- Excellent tool-use loop implementation
- MCP-native architecture
The trade-off: Higher model lock-in than LangGraph, and the safety features add latency.
Best for: Security-sensitive applications, autonomous agents operating with elevated permissions, and regulated industries.
5. Google ADK — GCP-Native Multimodal Agents
Google’s Agent Development Kit (ADK) targets teams building on Google Cloud. It offers tight integration with Gemini models, Vertex AI, and Google’s multimodal capabilities. The 11,000 GitHub stars show steady adoption among GCP users.
Why teams choose it:
- Native Gemini integration with multimodal support (text, image, audio, video)
- Seamless Vertex AI deployment
- Strong Google Cloud service integrations
- Competitive inference pricing through GCP
The trade-off: GCP ecosystem lock-in. Teams not on Google Cloud will find limited value.
Best for: Teams already on GCP building multimodal agents requiring Google’s model capabilities.
Framework Comparison: Side-by-Side
| Framework | Best For | Learning Curve | Model Lock-in | GitHub Stars |
|---|---|---|---|---|
| LangGraph | Complex production workflows | Medium-High | Low | ~126K |
| CrewAI | Fast prototyping | Low | Low | ~28K |
| OpenAI SDK | OpenAI-native teams | Low | Medium | ~18K |
| Claude SDK | Security-first applications | Medium | High | ~14K |
| Google ADK | GCP multimodal agents | Medium | Medium-High | ~11K |
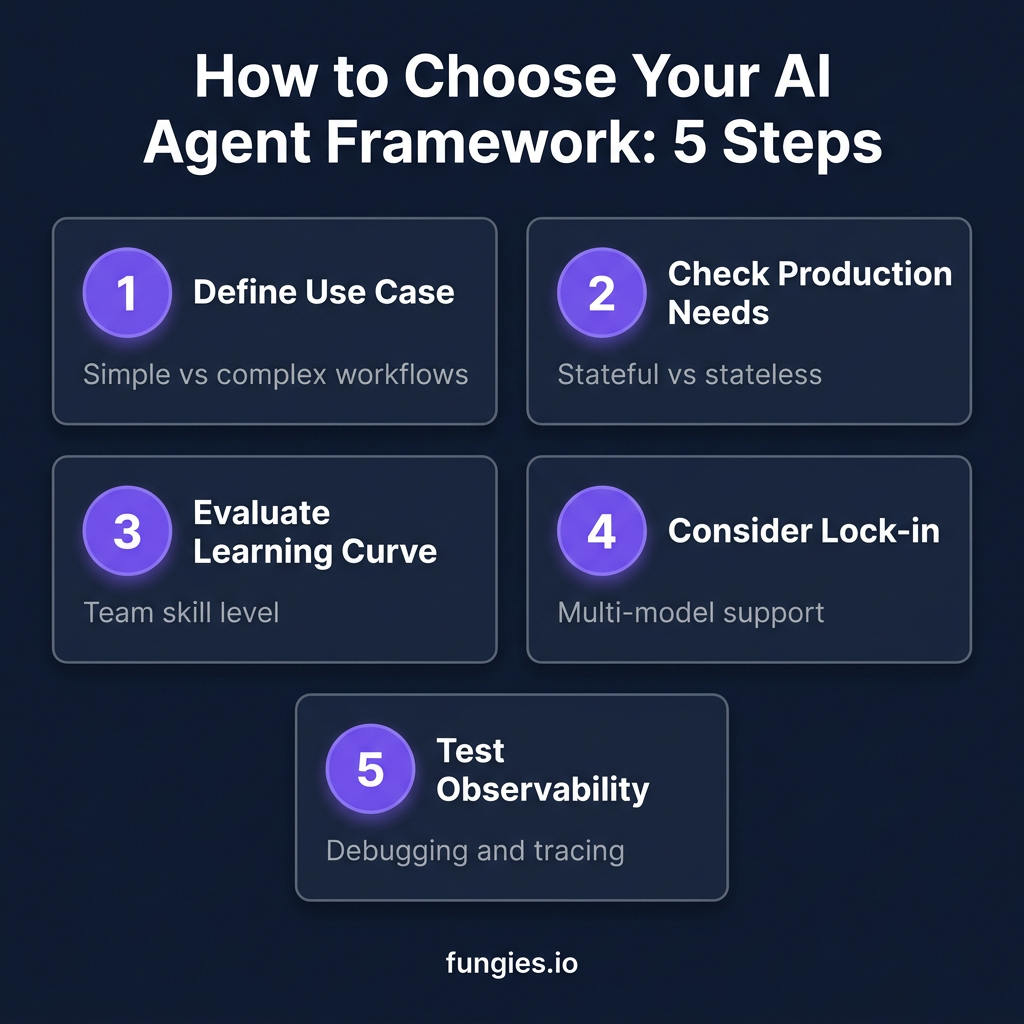
How to Choose: A Decision Framework
Here’s the decision tree I use with clients:
Step 1: Define Your Complexity
Simple agents (single tool calls, straightforward tasks) can use any framework. Complex workflows (multi-step reasoning, conditional branching, human approvals) need LangGraph’s explicit state management.
Step 2: Evaluate Production Requirements
Ask yourself: What happens when this fails at 2 AM? If you need checkpointing, time-travel debugging, and audit trails, LangGraph is your answer. If you’re building a prototype to validate an idea, CrewAI will get you there faster.
Step 3: Consider Team Expertise
A mid-level Python developer can build with CrewAI in a day. LangGraph requires understanding graph concepts and state machines. Be honest about your team’s capacity to learn new abstractions.
Step 4: Assess Model Flexibility
If you need to switch between OpenAI, Anthropic, and open-source models, avoid provider-specific SDKs. LangGraph and CrewAI both support 100+ models through standard interfaces.
Step 5: Test Observability
Before committing, verify you can trace agent execution. Build a simple agent, run it, and confirm you can see exactly what happened at each step. If debugging feels like archaeology, pick a different framework.
Code Example: Your First LangGraph Agent
Here’s a minimal example showing LangGraph’s explicit state management:
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
class AgentState(TypedDict):
query: str
context: list[str]
response: str
requires_human_review: bool
def analyze_query(state: AgentState):
# Analysis logic here
state["requires_human_review"] = len(state["query"]) > 100
return state
def route_after_analysis(state: AgentState) -> str:
if state["requires_human_review"]:
return "human_review"
return "generate_response"
# Build the graph
workflow = StateGraph(AgentState)
workflow.add_node("analyze", analyze_query)
workflow.add_node("human_review", human_review_node)
workflow.add_node("generate", generate_response_node)
workflow.add_edge("analyze", route_after_analysis)
workflow.add_edge("human_review", "generate")
workflow.add_edge("generate", END)
workflow.set_entry_point("analyze")
app = workflow.compile()
# Run with checkpointing
result = app.invoke(
{"query": "Process this insurance claim"},
config={"configurable": {"thread_id": "claim-123"}}
)
The key insight: every transition is explicit. You know exactly what happens at each step, and you can pause, resume, or replay from any checkpoint.
Common Mistakes to Avoid
After reviewing dozens of agent implementations, I see the same mistakes repeatedly:
Mistake 1: Choosing Based on GitHub Stars Alone
Stars measure popularity, not fitness for your use case. A framework with 100K stars that lacks checkpointing will fail in production when a simpler tool with 10K stars would succeed.
Mistake 2: Ignoring Cost Predictability
Inference now accounts for 55% of AI cloud spending—$37.5 billion in early 2026. Frameworks that allow unbounded LLM calls in loops are CFO nightmares. Always implement token limits and cost tracking from day one.
Mistake 3: Skipping Error Handling
Demo code never shows what happens when an API times out or returns malformed data. Production agents need explicit error handling, retry logic, and graceful degradation.
Mistake 4: Building Without Observability
If you can’t trace exactly what your agent did, you can’t debug it. Implement structured logging and tracing before your first production deployment.
Key Takeaways
- LangGraph is the production standard for complex, stateful workflows requiring audit trails and reliability
- CrewAI offers the fastest path to working multi-agent prototypes with minimal learning curve
- Provider SDKs (OpenAI, Claude, Google) work best when you’re already committed to their ecosystems
- Framework choice depends on three factors: failure tolerance, observability needs, and team debugging capacity
- Always test observability and error handling before committing to a framework
Frequently Asked Questions
What’s the easiest AI agent framework for beginners?
CrewAI has the lowest learning curve. You can build a working multi-agent system in 2-4 hours without understanding graph concepts or state machines.
Can I switch frameworks later?
Yes, but it costs time. Framework-agnostic tools like LangGraph and CrewAI make migration easier than provider-specific SDKs. Plan for 2-4 weeks of refactoring when switching.
Do I need a framework for simple agents?
For single-tool agents with straightforward tasks, you can use direct API calls. But once you need multi-step reasoning, error recovery, or human oversight, a framework saves significant development time.
Which framework has the best observability?
LangGraph with LangSmith provides the most comprehensive observability, including step-by-step execution traces, state inspection, and time-travel debugging.
Are these frameworks free to use?
All five frameworks are open-source (MIT or Apache 2.0 licenses). Your costs come from LLM inference, not the frameworks themselves. Budget $0.10-$25 per million tokens depending on your model choice.
Conclusion
Choosing an AI agent framework in 2026 isn’t about finding the “best” tool—it’s about finding the right tool for your specific constraints. LangGraph wins for production complexity. CrewAI wins for rapid prototyping. Provider SDKs win when you’re already committed to their ecosystems.
The teams that succeed don’t just pick a framework—they validate it against their actual failure modes before committing. Build a prototype, test the observability, simulate some failures, and confirm your team can debug it at 2 AM. That’s the only comparison that matters.
Ready to build your first AI-powered application? Get started with Fungies.io—we handle payments, tax compliance, and checkout so you can focus on building great products.
References
- Airbyte — Best AI Agent Frameworks 2026: https://airbyte.com/agentic-data/best-ai-agent-frameworks-2026
- Firecrawl — Best Open Source Agent Frameworks: https://www.firecrawl.dev/blog/best-open-source-agent-frameworks
- Pickaxe — Top 15 AI Agent Frameworks in 2026: https://pickaxe.co/post/top-ai-agent-frameworks
- Towards AI — Top AI Agent Frameworks in 2026: https://pub.towardsai.net/top-ai-agent-frameworks-in-2026
- AlphaCorp — The 8 Best AI Agent Frameworks in 2026: https://alphacorp.ai/blog/the-8-best-ai-agent-frameworks-in-2026



