Choosing the wrong LLM API can cost your SaaS thousands of dollars per month. In 2026, the price gap between the cheapest and most expensive models has widened to 100x—while performance differences have shrunk.
DeepSeek V3.2 costs $0.28 per million input tokens. Claude Opus 4.6 costs $5.00. That’s an 18x difference for input costs alone. Yet for many tasks, the cheaper model performs nearly as well.
This guide breaks down real LLM API pricing for 2026, compares performance benchmarks, and shows you exactly how to pick the right model for your use case—whether you’re building AI features, automating workflows, or powering customer support.

Why LLM API Pricing Matters for SaaS
If you’re integrating AI into your SaaS product, API costs directly impact your margins. A customer support bot that processes 10 million tokens monthly costs:
- $2.80 with DeepSeek V3.2 (8M input + 2M output tokens)
- $50.00 with Claude Opus 4.6 (same volume)
- $25.00 with GPT-5.4 (same volume)
That’s a $47 monthly difference per customer. At 1,000 customers, you’re looking at $564,000 in annual savings just from choosing the right model.
But price isn’t everything. The model that saves you money on simple tasks might cost you customers if it hallucinates on complex queries. The key is matching the model to the task.
LLM API Pricing Comparison 2026: The Complete Breakdown
Here’s the current pricing landscape for the major LLM providers as of April 2026. All prices are per million tokens.
| Model | Provider | Input | Output | Context Window |
|---|---|---|---|---|
| DeepSeek V3.2 | DeepSeek | $0.28 | $0.42 | 64K |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | |
| GPT-5.4 Nano | OpenAI | $0.20 | $0.80 | 128K |
| GPT-5.4 Mini | OpenAI | $0.75 | $3.00 | 128K |
| GPT-5.1 | OpenAI | $1.25 | $10.00 | 256K |
| GPT-5.2 | OpenAI | $1.75 | $14.00 | 512K |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | |
| GPT-5.4 | OpenAI | $2.50 | $15.00 | 1M |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 | 200K (1M beta) |
| Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | 200K (1M beta) |
Source: Official provider pricing pages, April 2026. Prices subject to change.
Performance Benchmarks: What You Get for the Price
Price means nothing without performance. Here’s how these models stack up on key benchmarks that matter for SaaS applications.
Coding Performance (HumanEval + LiveCodeBench)
| Model | HumanEval | LiveCodeBench | Price/Performance |
|---|---|---|---|
| Claude Opus 4.6 | 92.7% | 87.3% | Premium |
| DeepSeek V4 | 90.2% | 85.1% | Best Value |
| GPT-5.4 | 89.5% | 84.2% | Good |
| Claude Sonnet 4.6 | 86.4% | 81.7% | Fair |
| Gemini 2.5 Pro | 85.1% | 79.8% | Good |
| DeepSeek V3.2 | 82.3% | 76.4% | Excellent |
General Knowledge & Reasoning (MMLU-Pro + GPQA Diamond)
| Model | MMLU-Pro | GPQA Diamond | Use Case |
|---|---|---|---|
| Claude Opus 4.6 | 86.2% | 84.4% | Research, complex analysis |
| GPT-5.4 | 84.7% | 80.1% | General knowledge Q&A |
| Gemini 3.1 Pro | 83.9% | 78.5% | Multilingual applications |
| Claude Sonnet 4.6 | 80.3% | 75.2% | Balanced reasoning tasks |
| GPT-5.2 | 78.1% | 72.4% | Standard business queries |
Sources: TokenMix LLM Leaderboard 2026, Vellum AI Leaderboard
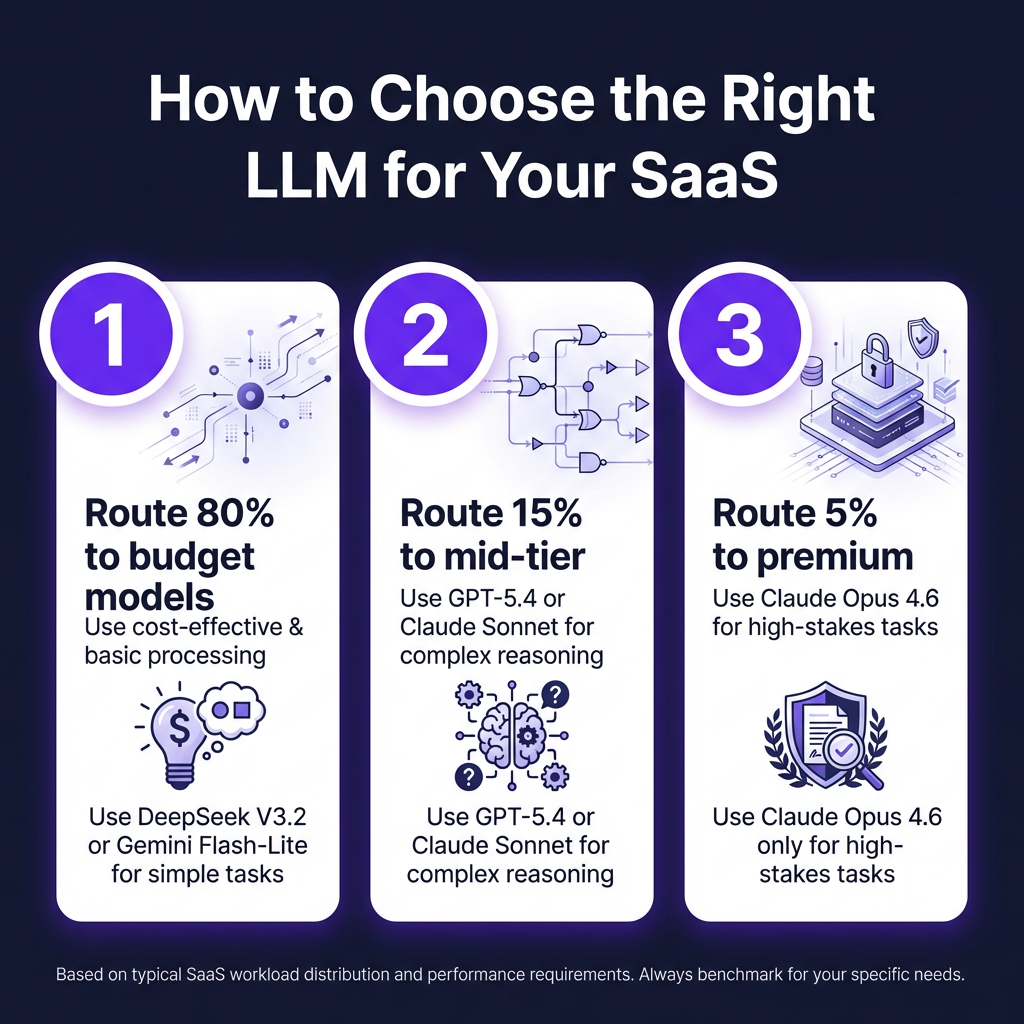
How to Choose the Right LLM for Your SaaS
The best approach isn’t picking one model—it’s building a routing strategy. Here’s how successful SaaS teams structure their LLM usage in 2026.
1. The 80/20 Routing Strategy
Route 80-95% of routine traffic to budget models, and escalate complex tasks to frontier models:
- Tier 1 (80% of traffic): DeepSeek V3.2, Gemini 2.5 Flash-Lite, or GPT-5.4 Nano for simple classification, summarization, and routine queries
- Tier 2 (15% of traffic): GPT-5.4, Gemini 2.5 Pro, or Claude Sonnet 4.6 for complex reasoning and customer-facing features
- Tier 3 (5% of traffic): Claude Opus 4.6 or GPT-5.4 Pro for high-stakes reasoning, legal analysis, and critical decisions
This approach typically reduces API costs by 60-80% while maintaining 95%+ of the quality.
2. Match Model to Use Case
| Use Case | Recommended Model | Why |
|---|---|---|
| Customer support chatbot | Gemini 2.5 Flash | 1M context, fast, cheap |
| Code generation / IDE | Claude Opus 4.6 | Best coding benchmarks |
| Document analysis | Gemini 2.5 Pro | 2M context window |
| Content summarization | DeepSeek V3.2 | Cheapest capable option |
| API routing / classification | GPT-5.4 Nano | Fastest, cheapest |
| Multi-agent workflows | Claude Sonnet 4.6 | Good tool use, balanced cost |
3. Consider Context Window Requirements
Context window size determines how much information the model can process at once. This matters for:
- Document analysis: Legal contracts, research papers, codebases
- Conversation history: Long customer support threads
- RAG applications: Retrieving multiple document chunks
| Context Need | Recommended Models |
|---|---|
| Standard (128K) | GPT-5.4, GPT-5.4 Mini, GPT-5.4 Nano |
| Large (200K-512K) | Claude Sonnet 4.6, GPT-5.2 |
| Massive (1M+) | Gemini 2.5 Pro, Gemini 2.5 Flash, Claude Opus 4.6 (beta) |
| Extreme (2M) | Gemini 3.1 Pro, Grok (xAI) |
Hidden Costs That Impact Your Bill
Beyond the per-token price, several factors can multiply your costs:
1. Long Context Premium Pricing
Claude charges premium rates for requests over 200K tokens. When you enable the 1M context window beta, all tokens are charged at $10 input / $37.50 output per million—double the standard rate.
2. Cached Input Discounts
Most providers offer 50-90% discounts on cached/repeated input tokens:
- OpenAI GPT-5.x: 90% discount on cached input
- DeepSeek V3.2: $0.028 per million for cache hits (vs $0.28 cache miss)
- Anthropic Claude: Prompt caching available for repeated system prompts
If you’re sending similar prompts repeatedly, caching can cut costs by 70%+.
3. Rate Limits and Throughput
Cheap models often have stricter rate limits. If you need high throughput, you might need to pay for higher tiers or use multiple providers.
4. Output Token Length
Output tokens usually cost 2-5x more than input tokens. A model that generates verbose responses can quickly become expensive. Claude Opus 4.6 charges $25 per million output tokens—60x more than DeepSeek V3.2’s $0.42.
Real-World Cost Scenarios for SaaS
Here are three realistic scenarios to help you estimate your costs.
Scenario 1: Customer Support Chatbot
Volume: 100,000 conversations/month, 2K input + 500 output tokens each
| Model | Monthly Cost |
|---|---|
| DeepSeek V3.2 | $77 |
| Gemini 2.5 Flash | $185 |
| GPT-5.4 | $1,250 |
| Claude Sonnet 4.6 | $1,350 |
Scenario 2: AI Coding Assistant
Volume: 10,000 code generations/month, 10K input + 2K output tokens each
| Model | Monthly Cost |
|---|---|
| DeepSeek V3.2 | $36 |
| GPT-5.4 | $550 |
| Claude Opus 4.6 | $1,000 |
Scenario 3: Document Analysis (RAG)
Volume: 50,000 documents/month, 50K input + 1K output tokens each
| Model | Monthly Cost |
|---|---|
| Gemini 2.5 Flash-Lite | $270 |
| Gemini 2.5 Pro | $3,125 |
| Claude Opus 4.6 (long context) | $21,875 |
Key Takeaways: Choosing Your LLM API Strategy
Here’s what matters when selecting an LLM API for your SaaS in 2026:
- Start cheap, escalate smart: Use DeepSeek V3.2 or Gemini Flash-Lite for 80%+ of tasks. Only use premium models when the task complexity justifies the cost.
- Benchmark your actual use case: Generic benchmarks don’t matter. Test models on your specific tasks with your data.
- Consider total cost, not just input price: Output tokens, context premiums, and caching can change the economics significantly.
- Don’t ignore context windows: If you process long documents, Gemini’s 1M-2M context can be worth the premium over models that require chunking.
- Build for switching: Use OpenAI-compatible APIs or abstraction layers so you can switch models as pricing and performance evolve.
FAQ: LLM API Pricing 2026
What is the cheapest LLM API in 2026?
DeepSeek V3.2 is the cheapest capable LLM at $0.28 per million input tokens and $0.42 per million output tokens. Google’s Gemini 2.5 Flash-Lite is even cheaper at $0.10/$0.40 but with slightly lower capability.
Is Claude Opus 4.6 worth the price?
For coding tasks and complex reasoning, yes. Claude Opus 4.6 leads most coding benchmarks with 92.7% on HumanEval. But for simple classification or summarization, you’re paying 18x more than DeepSeek for minimal quality improvement.
Which LLM has the largest context window?
Google’s Gemini 3.1 Pro and xAI’s Grok models offer 2 million token context windows—enough for entire books or massive codebases. Claude Opus 4.6 and Gemini 2.5 models offer 1 million tokens.
How can I reduce my LLM API costs?
Use prompt caching (50-90% savings), implement model routing (60-80% savings), optimize output length limits, and choose the right model tier for each task. Most SaaS teams can cut costs by 70%+ with these strategies.
What’s the best LLM for SaaS startups?
Start with Gemini 2.5 Flash or DeepSeek V3.2 for most tasks. They’re capable, cheap, and have generous free tiers. Upgrade to GPT-5.4 or Claude Sonnet 4.6 only when you need better performance on specific tasks.
Conclusion
LLM API pricing in 2026 spans a 100x range—from $0.10 to $25 per million tokens. The smart play isn’t using the most expensive model for everything. It’s building a routing strategy that matches model capability to task complexity.
Start with budget models for routine tasks. Reserve premium models for high-stakes reasoning. Implement caching. Monitor your costs per task type. The teams that master this will have a massive cost advantage over those blindly calling Claude Opus for every request.
Building a SaaS that needs to handle payments, taxes, and compliance? Get started with Fungies—the Merchant of Record platform that lets you focus on your AI features while we handle the financial infrastructure.
References
- Claude API Pricing Guide 2026 – DevTk.AI
- GPT-5 API Pricing Comparison 2026 – EvoLink
- Gemini API Pricing 2026 – TLDL
- DeepSeek API Pricing 2026 – DevTk.AI
- LLM Leaderboard and Benchmark Guide 2026 – TokenMix
- LLM Leaderboard 2026 – Vellum AI
- OpenAI API Cost In 2026 – CloudZero
- LLM API Pricing 2026 – Cloudidr




