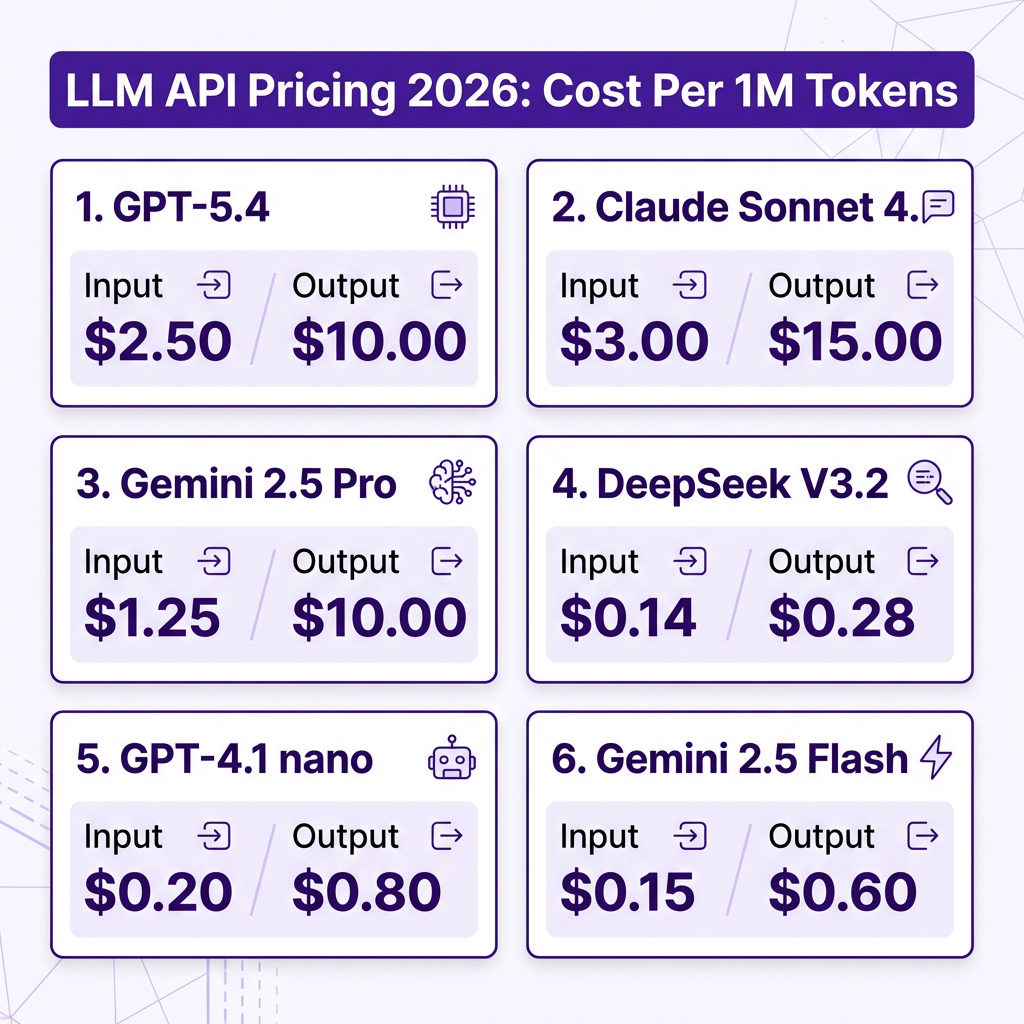
Here’s a number that should get your attention: DeepSeek V3.2 costs 100x less than GPT-5 for output tokens—$0.28 vs $30 per million. Yet most SaaS developers are still overpaying for LLM APIs because they don’t understand the pricing landscape.
In 2026, the gap between the most expensive and most affordable high-quality LLMs has never been wider. GPT-5.4 will run you $2.50 per million input tokens, while Gemini 2.5 Flash costs just $0.15. That’s a 16x difference—for models that can handle many of the same tasks.
This guide breaks down every major LLM API pricing tier, shows you exactly what you’re paying for, and gives you a framework for choosing the right model for your SaaS without bleeding money.
How LLM API Pricing Works in 2026
Before we compare models, you need to understand how providers charge. Every major LLM API uses token-based pricing, but the details matter.
Input vs Output Tokens
Providers charge separately for:
- Input tokens: Everything you send to the model (prompts, context, conversation history)
- Output tokens: Everything the model generates (responses, code, summaries)
Output tokens cost 2-10x more than input tokens across all providers. This matters because some models are “chatty”—they generate long responses that drive up your bill.
Context Window Pricing
Most providers charge the same rate regardless of context window size, but some offer discounts for cached context. Google’s Gemini offers up to 1 million tokens of context at standard pricing—a massive advantage for applications that need to process large documents or codebases.
Batch and Volume Discounts
OpenAI, Anthropic, and Google all offer batch processing discounts—typically 50% off for requests that can wait up to 24 hours. If you’re processing non-time-sensitive data (like nightly reports or content generation), batching cuts costs in half.
Complete LLM API Pricing Comparison (April 2026)
Here’s the current pricing for every major model you should consider for your SaaS:
| Model | Provider | Input (per 1M) | Output (per 1M) | Context | Best For |
|---|---|---|---|---|---|
| GPT-5.4 | OpenAI | $2.50 | $10.00 | 128K | General purpose |
| GPT-5.4 mini | OpenAI | $0.55 | $2.19 | 128K | Cost-sensitive tasks |
| GPT-4.1 nano | OpenAI | $0.20 | $0.80 | 128K | Simple classification |
| Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | 200K | Complex reasoning |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 | 200K | Writing & coding |
| Claude Haiku 4.5 | Anthropic | $0.25 | $1.25 | 200K | Fast responses |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | Long documents | |
| Gemini 2.5 Flash | $0.15 | $0.60 | 1M | High volume | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | Cheapest option | |
| DeepSeek V3.2 | DeepSeek | $0.14 | $0.28 | 128K | Budget workloads |
| Grok 3 | xAI | $2.00 | $10.00 | 128K | X integration |
| Mistral Large | Mistral | $2.00 | $6.00 | 128K | EU compliance |
| Mistral Small | Mistral | $0.20 | $0.60 | 128K | Cost-efficient EU |
Real-World Cost Examples
Let’s look at what these prices mean for actual SaaS use cases:
Customer Support Chatbot (10,000 conversations/month)
Average 500 tokens input, 200 tokens output per conversation:
| Model | Monthly Cost |
|---|---|
| GPT-5.4 | $32.50 |
| Claude Sonnet 4.6 | $48.00 |
| Gemini 2.5 Flash | $1.95 |
| DeepSeek V3.2 | $1.26 |
| GPT-4.1 nano | $1.16 |
Code Generation Assistant (50,000 requests/month)
Average 1,000 tokens input, 500 tokens output per request:
| Model | Monthly Cost |
|---|---|
| GPT-5.4 | $375.00 |
| Claude Sonnet 4.6 | $525.00 |
| Gemini 2.5 Pro | $187.50 |
| DeepSeek V3.2 | $21.00 |
Content Generation Pipeline (100,000 articles/month)
Average 2,000 tokens input, 1,500 tokens output per article:
| Model | Monthly Cost |
|---|---|
| GPT-5.4 | $2,000.00 |
| Claude Sonnet 4.6 | $2,850.00 |
| Gemini 2.5 Flash | $120.00 |
| DeepSeek V3.2 | $70.00 |
How to Choose the Right Model for Your Use Case
Price isn’t everything. Here’s how to match models to tasks:
For Simple Classification and Tagging
Use: GPT-4.1 nano, Gemini 2.5 Flash-Lite, or DeepSeek V3.2
These tasks don’t require reasoning power. Sentiment analysis, spam detection, and content categorization work fine on budget models at a fraction of the cost.
For Customer-Facing Chatbots
Use: Claude Sonnet 4.6 or Gemini 2.5 Pro
Claude excels at maintaining helpful, harmless conversations. Gemini 2.5 Pro offers the best value for high-volume applications with its 1M context window.
For Code Generation and Technical Tasks
Use: Claude Sonnet 4.6 or GPT-5.4
Claude consistently scores higher on coding benchmarks (SWE-bench Verified: 77.4% for Claude Code vs competitors). GPT-5.4 is a solid alternative with broader tool ecosystem support.
For Complex Reasoning and Analysis
Use: Claude Opus 4.6 or GPT-5.4 Pro
When you need multi-step reasoning, mathematical analysis, or handling ambiguous requirements, the premium models justify their cost. Reserve these for high-stakes decisions.
For Document Processing and RAG
Use: Gemini 2.5 Pro or Gemini 2.5 Flash
The 1 million token context window changes the game for RAG applications. You can fit entire documents or large codebases in a single prompt without chunking.
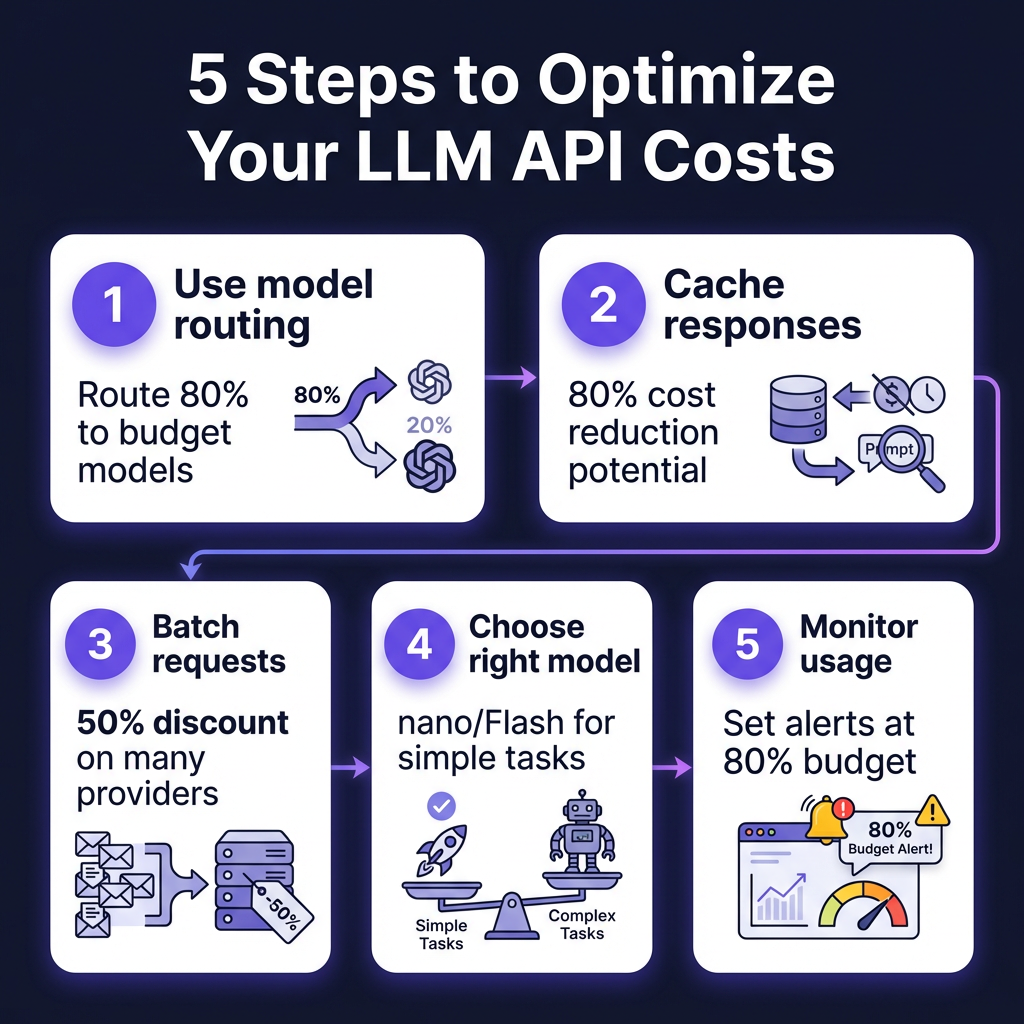
5 Cost Optimization Strategies That Actually Work
1. Implement Model Routing
Route 80% of routine queries to budget models (Gemini Flash, GPT-4.1 nano, DeepSeek) and reserve premium models for complex tasks. Services like OpenRouter or LiteLLM make this trivial to implement.
2. Cache Aggressively
A 1-hour cache on AI responses can cut costs by 80%+ for repeated queries. Common questions, standard code patterns, and template responses should never hit the API twice.
3. Use Batch Processing
For non-time-sensitive workloads (nightly reports, content generation, data enrichment), batching saves 50% on OpenAI and Anthropic APIs.
4. Optimize Your Prompts
Every token counts. Use system prompts efficiently, remove unnecessary context, and ask for concise responses when possible. A 20% reduction in token usage equals a 20% cost reduction.
5. Set Usage Alerts and Budgets
All major providers offer spending alerts. Set them at 50%, 80%, and 100% of your budget. Unexpected API bills have killed early-stage SaaS companies.
Hidden Costs to Watch For
Beyond token pricing, factor in these costs:
- Context window bloat: MCP servers can consume 8,000+ tokens just for tool descriptions
- Retries and errors: Failed requests still count toward billing on most providers
- Embedding costs: If you’re doing RAG, OpenAI’s text-embedding-3-large costs $0.13 per million tokens
- Image and multimodal: Vision API calls cost 5-15x more than text-only
- Infrastructure overhead: Add 25-30% for orchestration, monitoring, and failover
Key Takeaways
- The price gap between budget and premium models is now 100x—choose wisely
- Gemini 2.5 Flash and DeepSeek V3.2 offer the best price-performance for most SaaS use cases
- Claude Sonnet 4.6 justifies its premium for customer-facing and coding applications
- Implement model routing to cut costs by 60-80% without sacrificing quality
- Batch processing and caching are free money—use them
FAQ
What’s the cheapest LLM API for high-volume SaaS?
DeepSeek V3.2 at $0.14/$0.28 per million tokens is currently the cheapest high-quality option. Gemini 2.5 Flash-Lite at $0.10/$0.40 is even cheaper but with slightly lower capability.
Is GPT-5 worth the premium over GPT-4.1?
For most SaaS applications, no. GPT-4.1 nano and mini handle 80% of tasks at 10-20% of the cost. Reserve GPT-5 for complex reasoning where accuracy directly impacts revenue.
How do I estimate my LLM API costs?
Start with your expected monthly requests, estimate average input/output tokens per request, multiply by the per-million token price, then add 25-30% for overhead and growth.
Can I switch between LLM providers easily?
Yes. Use an abstraction layer like LiteLLM, OpenRouter, or the Vercel AI SDK. They provide a unified API across providers, making swaps a configuration change rather than a code rewrite.
Do I need a separate API key for each provider?
Yes, each provider requires their own API key. However, services like OpenRouter or Together AI let you access multiple models with a single key—often at discounted rates.
Conclusion
LLM API pricing in 2026 is a buyer’s market if you know what you’re doing. The gap between budget and premium models has never been wider, and smart routing lets you get 90% of the capability at 10% of the cost.
Start with Gemini 2.5 Flash or DeepSeek V3.2 for most tasks. Upgrade to Claude Sonnet or GPT-5 only when you have specific quality requirements that justify the 10-20x price premium.
And remember—every dollar you save on AI infrastructure is a dollar you can spend on acquiring customers.
Ready to build your SaaS with optimized AI costs? Get started with Fungies—we handle payments, tax compliance, and checkout so you can focus on building great AI-powered products.