Here’s a number that should get your attention: the cheapest LLM API costs 20x less than the most expensive option for the same task. In 2026, choosing the wrong model for your workload can cost you thousands per month—or deliver subpar results that hurt your product.
I’ve analyzed pricing from OpenAI, Anthropic, Google, and DeepSeek to give you the real numbers. No marketing fluff. Just data you can use to cut your AI infrastructure costs without sacrificing quality.

Why LLM API Pricing Matters More Than Ever in 2026
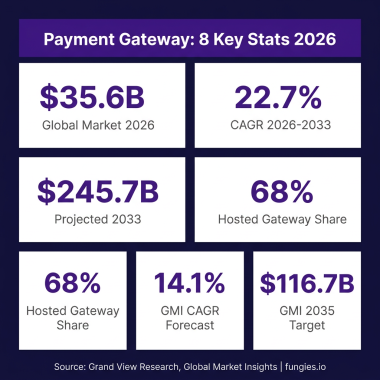
The AI code tools market hit $8.5 billion in 2026, and inference costs now represent 55% of AI cloud spending—that’s $37.5 billion in early 2026 alone. If you’re building with AI, your API bill is likely your second-largest infrastructure cost after compute.
But here’s what most developers miss: price per token isn’t the whole story. Context window size, output quality, and caching options can swing your actual costs by 5-10x. A model that looks cheap on paper might cost more in practice if it needs multiple attempts to get the answer right.
LLM API Pricing Comparison: The Complete 2026 Breakdown
I’ve compiled pricing from official API documentation as of June 2026. All prices are per million tokens. Input = what you send to the model. Output = what the model generates.
| Model | Input | Output | Context | Best For |
|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | Cost-sensitive batch jobs |
| Gemini 2.5 Flash | $0.15 | $0.60 | 1M | Long docs, reasoning |
| GPT-4.1 Nano | $0.10 | $0.40 | 128K | Simple classification |
| DeepSeek V3.2 | $0.14 | $0.28 | 128K | Open-source alternative |
| GPT-4.1 Mini | $0.40 | $1.60 | 128K | Balanced price/quality |
| GPT-4.1 | $2.00 | $15.00 | 128K | General production use |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K | Code, reasoning |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M | Multimodal tasks |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M beta | Complex agent workflows |
| GPT-4o | $2.50 | $10.00 | 128K | Vision + text |
The 5 Cheapest LLM APIs for Developers in 2026
If your primary concern is cost, these five models deliver the best price-to-performance ratio for most use cases:
1. Gemini 2.5 Flash-Lite — $0.10 per Million Input Tokens
Google’s Flash-Lite is the cheapest production-ready LLM on the market. At $0.10 per million input tokens, it’s 50x cheaper than Claude Opus. The trade-off? It’s best for straightforward tasks: summarization, classification, and simple Q&A.
When to use it: Batch processing, document ingestion, simple chatbots, and any workload where speed matters more than creative reasoning.
2. Gemini 2.5 Flash — $0.15 per Million Input Tokens
For just 50% more than Flash-Lite, you get significantly better reasoning capabilities and the same massive 1 million token context window. This is Google’s sweet spot for most developers.
When to use it: RAG applications, long document analysis, and multi-turn conversations where you need more than basic pattern matching.
3. GPT-4.1 Nano — $0.10 per Million Input Tokens
OpenAI’s Nano model matches Google’s pricing but with a smaller 128K context window. It’s optimized for speed and cost, not depth.
When to use it: Simple classification, entity extraction, and high-volume applications where latency is critical.
4. DeepSeek V3.2 — $0.14 per Million Input Tokens
The open-source challenger. DeepSeek V3.2 offers competitive pricing with an OpenAI-compatible API. At $0.14/$0.28 per million tokens, it’s a viable alternative if you want to avoid vendor lock-in.
When to use it: Self-hosted deployments, privacy-sensitive applications, and teams building on open-source infrastructure.
5. GPT-4.1 Mini — $0.40 per Million Input Tokens
OpenAI’s Mini model hits the price-quality balance most production apps need. It’s 5x cheaper than GPT-4.1 but retains most of the capability for everyday tasks.
When to use it: Production applications that need reliable output without premium pricing. Most SaaS features fit here.

Premium LLM APIs: When to Pay More
Sometimes cheap isn’t the right choice. These three models justify their higher prices for specific use cases:
Claude Opus 4.6 — $5.00/$25.00 per Million Tokens
Anthropic’s flagship model leads on complex reasoning and agent workflows. The 1 million token context window (in beta) lets you process entire codebases in one request. At 50x the cost of Flash-Lite, it’s not for everything—but when you need the best reasoning available, this is it.
Real-world use case: A development team at a fintech company reduced their architecture review time from 3 days to 4 hours by feeding entire microservice codebases to Opus for analysis.
GPT-4.1 — $2.00/$15.00 per Million Tokens
OpenAI’s workhorse model delivers consistent quality across text, code, and vision tasks. The $0.50 cached input rate (75% discount) makes it cost-effective for repetitive workflows.
Real-world use case: A customer support platform cut their AI costs by 60% using prompt caching with GPT-4.1 for common troubleshooting flows.
Claude Sonnet 4.6 — $3.00/$15.00 per Million Tokens
The sweet spot for most Anthropic users. Sonnet 4.6 offers 91% CSAT and 54 NPS scores according to JetBrains’ April 2026 survey. It’s the most-loved AI coding tool at 46% preference—far ahead of Cursor (19%) and Copilot (9%).
Real-world use case: Developers using Claude Code report saving 7 hours per week on coding tasks, making the $20/month subscription pay for itself in the first day.
5 Strategies to Cut Your LLM API Costs by 60%
Smart developers don’t just pick the cheapest model—they optimize how they use it. Here are five tactics that actually work:
1. Implement Prompt Caching
OpenAI’s cached input pricing cuts costs by 75% for repeated prompts. Claude offers similar caching. If you’re sending the same system prompts or context repeatedly, caching is non-negotiable.
Potential savings: 50-75% for RAG applications and conversational agents.
2. Route Requests Smartly
Don’t use a sledgehammer for nails. Route 80-95% of traffic to cheap models (Gemini Flash-Lite, GPT-4.1 Nano) and escalate complex tasks to frontier models (Claude Opus, GPT-4.1).
Potential savings: 60-80% on overall token spend.
3. Batch Your Requests
Processing 100 requests individually costs more than one batch request with 100 items. Most APIs offer batching discounts or at least reduce overhead costs.
Potential savings: 20-40% for high-volume applications.
4. Trim Your Context Windows
That 1 million token context window is tempting, but you’re paying for every token you send. Pre-process documents to extract only relevant sections. Use chunking strategies for RAG instead of dumping entire files.
Potential savings: 30-70% depending on current context usage.
5. Monitor and Set Limits
Track spend per model, per feature, per user. Set hard limits and alerts. Many teams discover they’re spending 80% of their budget on 20% of features that could use cheaper models.
Potential savings: 25-50% through elimination of waste and unexpected usage spikes.
Real-World Cost Scenarios
Let’s look at what you’d actually pay for three common use cases:
| Use Case | Monthly Tokens | Gemini Flash | GPT-4.1 | Claude Opus |
|---|---|---|---|---|
| Customer Support Bot | 50M input / 10M output | $13.50 | $250 | $500 |
| Code Review Assistant | 20M input / 5M output | $6.00 | $115 | $225 |
| Document Analysis | 100M input / 20M output | $27.00 | $500 | $1,000 |
The numbers don’t lie: model selection alone can create 20x cost differences for the same workload. A startup processing 100M tokens monthly would pay $27 with Gemini Flash versus $1,000 with Claude Opus.
Key Takeaways: How to Choose the Right LLM API
- For cost-sensitive batch jobs: Gemini 2.5 Flash-Lite at $0.10/million tokens is unbeatable
- For production SaaS: GPT-4.1 Mini or Gemini 2.5 Flash offer the best price-quality balance
- For complex reasoning: Claude Sonnet 4.6 leads developer satisfaction at $3/$15 per million
- For agent workflows: Claude Opus 4.6 justifies its premium for autonomous multi-step tasks
- Always implement caching: 75% cost reduction on repeated prompts is too good to ignore
Frequently Asked Questions
What’s the cheapest LLM API in 2026?
Gemini 2.5 Flash-Lite and GPT-4.1 Nano both cost $0.10 per million input tokens, making them the cheapest production-ready options. However, Flash-Lite offers a 1M token context window versus Nano’s 128K.
Is Claude Opus worth the price?
For complex reasoning, code analysis, and agent workflows—yes. At $5/$25 per million tokens, it’s 50x more expensive than Flash-Lite, but it can complete tasks in one attempt that would require 5-10 tries with cheaper models. Do the math for your specific use case.
How much can prompt caching save?
OpenAI offers 75% discounts on cached inputs ($0.50 vs $2.00 for GPT-4.1). For applications with repetitive system prompts or RAG contexts, caching typically reduces costs by 50-75%.
What’s the best LLM API for coding?
According to JetBrains’ April 2026 survey, Claude Code is the most-loved AI coding tool at 46% preference, with 91% CSAT and 54 NPS. Developers report saving 7 hours per week. Claude Sonnet 4.6 at $3/$15 per million tokens offers the best balance of price and coding capability.
Should I use multiple LLM providers?
Yes. According to Faros AI analysis, successful engineering teams use 2-3 tools strategically—GitHub Copilot for day-to-day completions and a reasoning-focused tool like Claude Code for architectural work. The same applies to APIs: use cheap models for simple tasks, premium models for complex ones.
Conclusion: Pick the Right Tool for the Job
LLM API pricing in 2026 spans a 50x range—from $0.10 to $5.00 per million input tokens. The “best” model isn’t the cheapest or the most capable; it’s the one that matches your specific workload.
Start with Gemini 2.5 Flash for most tasks. Upgrade to GPT-4.1 or Claude Sonnet when you need more reliability. Reserve Claude Opus for the complex work that justifies the premium.
And whatever you choose—implement caching, batch your requests, and monitor your spend. The developers who master cost optimization will outcompete those who don’t.
Ready to build AI-powered features for your SaaS? Get started with Fungies and focus on your product while we handle payments, tax compliance, and global infrastructure.
References
- AI Superior — LLM Cost Comparison 2026
- PE Collective — Cross-Provider LLM API Pricing Comparison
- CloudIDR — LLM API Pricing 2026
- MorphLLM — LLM API Comparison 2026
- SurePrompts — Complete Guide to AI Models 2026
- IdeaPlan — AI Coding Tools 2026
- SitePoint — Claude Code vs Cursor vs Copilot 2026
- UVik — AI Coding Assistant Statistics 2026