Developers spent $4.7 billion on LLM APIs in 2025. That number is projected to hit $12 billion by the end of 2026. If you’re building AI-powered features into your SaaS, the API you choose directly impacts your margins, your latency, and your user experience.
Here’s the reality: GPT-5.4 Pro costs 600x more than GPT-5 nano. Claude Opus 4.6 will burn through your budget faster than a Series A startup at a cloud conference. But the most expensive model isn’t always the best choice—and the cheapest option might cost you customers.
This guide breaks down the 10 best LLM APIs for developers in 2026. Real pricing. Real benchmarks. Real recommendations for different use cases.
What We Evaluated
We ranked these APIs across five dimensions that actually matter to developers:
| Criteria | Weight | Why It Matters |
| **Pricing** | 25% | Direct impact on your COGS and margins |
|---|---|---|
| **Performance** | 25% | Quality scores on standard benchmarks |
| **Latency** | 20% | User experience and real-time feasibility |
| **Context Window** | 15% | How much data you can process in one call |
| **Developer Experience** | 15% | API reliability, documentation, tooling |
All pricing data is current as of April 2026. Prices are per million tokens unless noted.
The 10 Best LLM APIs Ranked
1. GPT-5.4 — The Production Workhorse
Pricing: $2.50/M input, $15/M output
Context Window: 128K tokens
Benchmark Score: 94/100
Best For: General-purpose production workloads
GPT-5.4 is the Model T of LLM APIs—reliable, well-documented, and everywhere. At $2.50 per million input tokens, it hits the sweet spot between capability and cost that most SaaS applications need.
The Numbers:
– 94 overall score on BenchLM.ai leaderboard
– 128K context window handles most document processing tasks
– ~400K input tokens per $1 of budget
– 800 conversations per dollar (at 500 tokens/conversation)
When to Use It:
– Chat interfaces and conversational AI
– Content generation and summarization
– Code completion and review
– Multi-step reasoning tasks
The Catch:
Output costs run $15/M—6x the input price. If your application generates long responses, budget accordingly. A customer support bot that writes detailed replies will spend more on output tokens than input.
2. Gemini 3.1 Pro — The Value Champion
Pricing: $1.25/M input, $5/M output
Context Window: 1M tokens
Benchmark Score: 94/100
Best For: High-volume applications, document processing
Google’s Gemini 3.1 Pro is the biggest surprise of 2026. It matches GPT-5.4’s 94 benchmark score at half the price. The 1 million token context window is 8x larger than GPT-5.4—and it’s not just marketing. You can actually process entire codebases, long legal documents, or hours of conversation history in a single call.
The Numbers:
– Same 94 score as GPT-5.4 at 50% of the cost
– 1M token context window (industry-leading)
– $0.0053 per 10-page document processed
– 18x cheaper than Claude Opus for document workloads
When to Use It:
– Document analysis and extraction
– RAG applications with large context needs
– Cost-sensitive production workloads
– Multi-modal applications (text + image + video)
The Catch:
Google’s API documentation isn’t as polished as OpenAI’s. The SDK has improved, but you’ll hit rough edges. Also, if your users care about data privacy, Google’s data handling policies need review.
3. Claude Sonnet 4.6 — The Coding Specialist
Pricing: $3.00/M input, $15/M output
Context Window: 200K tokens
Benchmark Score: 68/100 (coding: 85+)
Best For: Code generation, technical documentation, agentic workflows
Anthropic’s Sonnet 4.6 doesn’t win on overall benchmarks, but it dominates coding tasks. The 85+ score on SWE-bench Verified makes it the go-to choice for AI coding agents like Claude Code. The 200K context window strikes a balance—large enough for substantial codebases without the complexity of Gemini’s 1M window.
The Numbers:
– 85+ on coding-specific benchmarks
– 200K context window (2x GPT-5.4)
– $3/M input, $15/M output
– More sustainable than Opus for agentic workflows
When to Use It:
– AI coding assistants and agents
– Technical writing and documentation
– Complex reasoning tasks
– Applications requiring careful instruction following
The Catch:
The 68 overall score lags behind GPT-5.4 and Gemini 3.1 Pro. For general chat or creative writing, you’re overpaying. Also, Anthropic’s rate limits can be aggressive for new accounts.
4. DeepSeek V3 — The Budget Beast
Pricing: $0.27/M input, $1.10/M output
Context Window: 64K tokens
Benchmark Score: 72/100
Best For: High-volume, cost-sensitive applications
DeepSeek V3 proves you don’t need Silicon Valley pricing to get capable AI. At $0.27 per million input tokens, it’s 9x cheaper than GPT-5.4. The 72 benchmark score isn’t flagship-tier, but it’s solid for many production tasks.
The Numbers:
– 9x cheaper than GPT-5.4 on input
– 4x cheaper on output
– 72 overall benchmark score
– 64K context window
When to Use It:
– Classification and tagging
– Simple Q&A and chatbots
– High-volume preprocessing
– Applications where “good enough” beats “best”
The Catch:
DeepSeek is a Chinese company. Data residency and compliance questions exist. The API documentation is minimal compared to OpenAI or Anthropic. Support is community-driven.
5. GPT-5.4 Mini — The Lightweight Contender
Pricing: $0.15/M input, $0.60/M output
Context Window: 128K tokens
Benchmark Score: 82/100
Best For: Latency-sensitive applications, simple tasks
GPT-5.4 Mini delivers 82% of GPT-5.4’s capability at 6% of the price. The 128K context window matches its bigger sibling. For applications where speed matters more than absolute quality—form processing, simple classification, entity extraction—Mini is the pragmatic choice.
The Numbers:
– 82 benchmark score (competitive with flagship models from 2024)
– 17x cheaper than GPT-5.4
– Same 128K context window
– Significantly faster response times
When to Use It:
– Real-time applications
– Simple classification and extraction
– Form processing and data entry
– Applications with tight latency budgets
The Catch:
Complex reasoning and creative tasks show the quality gap. Don’t use Mini for code generation or nuanced content creation. It’s a scalpel, not a Swiss Army knife.
6. Claude Opus 4.6 — The Premium Option
Pricing: $15.00/M input, $75.00/M output
Context Window: 200K tokens
Benchmark Score: 85/100
Best For: High-stakes decisions, legal analysis, complex research
Claude Opus 4.6 is the Ferrari of LLM APIs—expensive, powerful, and unnecessary for daily driving. The 85 benchmark score leads Anthropic’s lineup. The reasoning capabilities are genuinely impressive. But at $15/M input and $75/M output, every call costs real money.
The Numbers:
– 85 overall benchmark score
– 6x more expensive than GPT-5.4 on input
– 5x more expensive on output
– Best-in-class reasoning and analysis
When to Use It:
– Legal document analysis
– Complex financial modeling
– High-stakes decision support
– Research and synthesis tasks
The Catch:
The cost is prohibitive for most applications. A single long conversation can cost dollars. Reserve Opus for tasks where errors are expensive and quality is paramount.
7. Grok 4.1 — The X Factor
Pricing: $3.00/M input, $15/M output
Context Window: 128K tokens
Benchmark Score: 76/100
Best For: Real-time information, X/Twitter integration
xAI’s Grok 4.1 offers something unique: real-time access to X/Twitter data. The 76 benchmark score is solid if not spectacular. But if your application needs current events, trending topics, or social sentiment, Grok is the only game in town.
The Numbers:
– 76 benchmark score
– Real-time X/Twitter data access
– $3/M input matches Claude Sonnet pricing
– 128K context window
When to Use It:
– Social media monitoring
– Real-time news analysis
– Trend detection and tracking
– Applications requiring current information
The Catch:
The “real-time” advantage is niche. For most applications, it’s an expensive novelty. The API is less mature than competitors. Documentation is sparse.
8. Mistral Large 3 — The European Alternative
Pricing: $2.00/M input, $6/M output
Context Window: 128K tokens
Benchmark Score: 78/100
Best For: GDPR compliance, European data residency
Mistral Large 3 is the best European LLM API. The 78 benchmark score is competitive. The $2/M input pricing undercuts GPT-5.4. For companies needing EU data residency or GDPR compliance, Mistral is the logical choice.
The Numbers:
– 78 benchmark score
– 20% cheaper than GPT-5.4
– EU-based infrastructure
– 128K context window
When to Use It:
– GDPR-compliant applications
– European data residency requirements
– Government and enterprise contracts
– Companies avoiding US-based providers
The Catch:
The ecosystem is smaller. Fewer integrations, less community support, thinner documentation. The 78 score lags behind GPT-5.4 and Gemini 3.1 Pro.
9. Gemini 3.1 Flash-Lite — The Ultra-Budget Option
Pricing: $0.10/M input, $0.40/M output
Context Window: 1M tokens
Benchmark Score: 65/100
Best For: Preprocessing, classification, high-volume batch jobs
Gemini 3.1 Flash-Lite is the cheapest way to access Google’s 1M token context window. At $0.10 per million input tokens, it’s 25x cheaper than GPT-5.4. The 65 benchmark score is the trade-off—you’re getting basic capability, but sometimes that’s all you need.
The Numbers:
– 25x cheaper than GPT-5.4
– Same 1M context window as Pro
– 65 benchmark score (usable for simple tasks)
– $0.0006 per 10-page document
When to Use It:
– Document preprocessing
– Initial classification and routing
– Batch processing jobs
– Applications where volume beats quality
The Catch:
Quality drops significantly on complex tasks. Don’t use Flash-Lite for customer-facing features unless you’ve validated output quality extensively.
10. GPT-5 nano — The Bare Minimum
Pricing: $0.05/M input, $0.40/M output
Context Window: 32K tokens
Benchmark Score: 58/100
Best For: Simple classification, entity extraction, routing
GPT-5 nano is the cheapest major LLM API on the market. At $0.05 per million tokens, it’s practically free. The 58 benchmark score reflects its limitations—this is a tool for simple, structured tasks, not creative work or complex reasoning.
The Numbers:
– Cheapest major LLM API available
– 50x cheaper than GPT-5.4
– 32K context window (smallest on this list)
– 58 benchmark score
When to Use It:
– Simple classification (spam detection, sentiment)
– Entity extraction
– Request routing
– Preprocessing before sending to larger models
The Catch:
The 32K context window is limiting. The 58 score means quality varies. Use nano for tasks with clear right/wrong answers, not nuanced generation.
Pricing Comparison Table
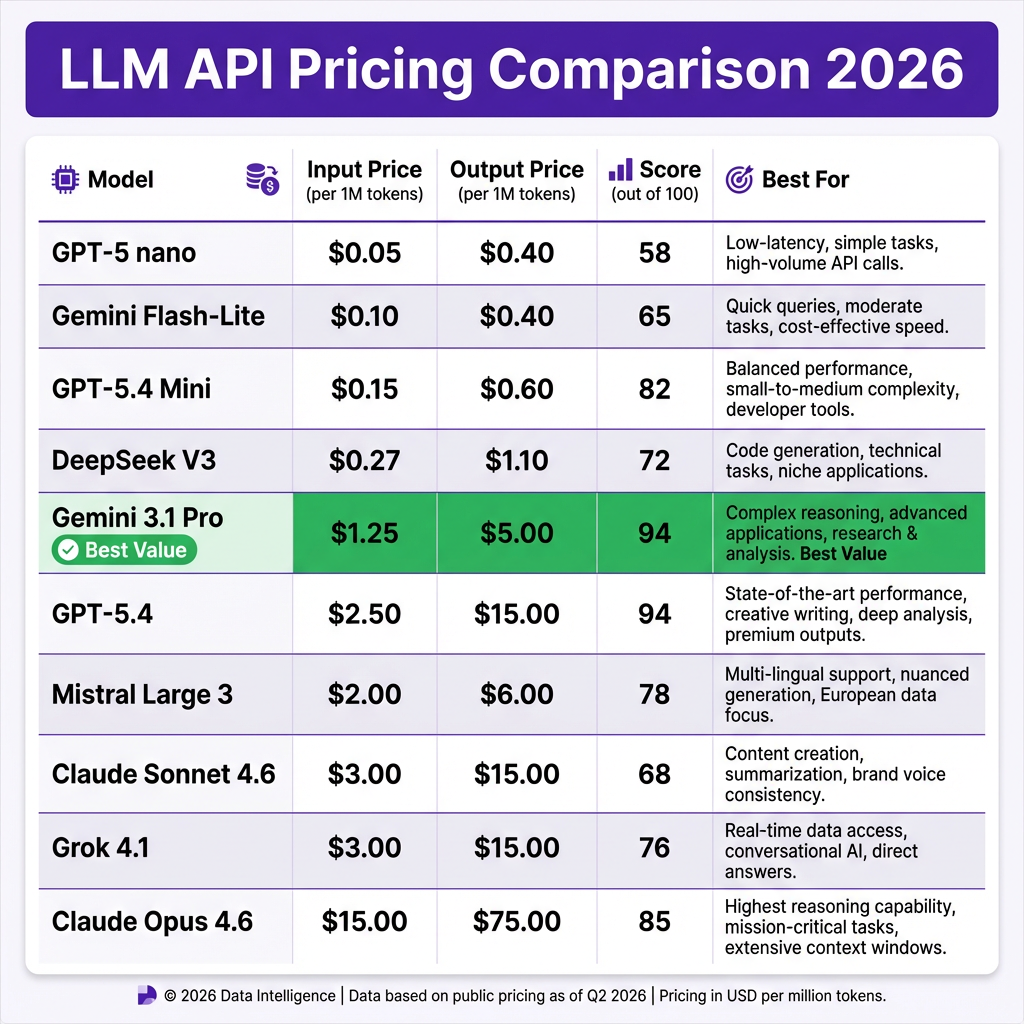
| Model | Input ($/M) | Output ($/M) | Score | Context | Cost/1K Calls* |
| GPT-5 nano | $0.05 | $0.40 | 58 | 32K | $0.09 |
|---|---|---|---|---|---|
| Gemini Flash-Lite | $0.10 | $0.40 | 65 | 1M | $0.10 |
| GPT-5.4 Mini | $0.15 | $0.60 | 82 | 128K | $0.19 |
| DeepSeek V3 | $0.27 | $1.10 | 72 | 64K | $0.34 |
| Gemini 3.1 Pro | $1.25 | $5.00 | 94 | 1M | $1.56 |
| GPT-5.4 | $2.50 | $15.00 | 94 | 128K | $3.63 |
| Mistral Large 3 | $2.00 | $6.00 | 78 | 128K | $2.40 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 68 | 200K | $4.05 |
| Grok 4.1 | $3.00 | $15.00 | 76 | 128K | $4.05 |
| Claude Opus 4.6 | $15.00 | $75.00 | 85 | 200K | $20.25 |
*Assumes 500 input tokens + 250 output tokens per call

How to Choose: Decision Framework
Step 1: Define Your Quality Bar
Not every application needs frontier-level AI. Ask honestly: what’s the minimum quality your users will accept?
– Minimum viable (58-65 score): GPT-5 nano, Gemini Flash-Lite
– Good enough (72-78 score): DeepSeek V3, Mistral Large 3, Grok 4.1
– Production quality (82-85 score): GPT-5.4 Mini, Claude Opus 4.6
– Frontier quality (94 score): GPT-5.4, Gemini 3.1 Pro
Step 2: Calculate Your Volume
At 1M tokens/month, the difference between GPT-5.4 ($2.50) and Claude Opus ($15) is $12,500/year. At 10M tokens/month, it’s $125,000/year.
Use this formula:
Monthly Cost = (Input Tokens × Input Price + Output Tokens × Output Price) / 1,000,000Step 3: Match Context to Task
| Task Type | Minimum Context | Recommended Model |
| Chat/Q&A | 4K | GPT-5.4 Mini |
|---|---|---|
| Code review | 32K | Claude Sonnet 4.6 |
| Document analysis | 128K | Gemini 3.1 Pro |
| Codebase-wide changes | 200K | Claude Sonnet 4.6 |
| Long-form content | 128K | GPT-5.4 |
| Multi-document synthesis | 1M | Gemini 3.1 Pro |
Step 4: Consider Latency Requirements
Smaller models are faster. If your application needs sub-500ms responses:
– GPT-5.4 Mini: ~200ms
– GPT-5.4: ~500ms
– Claude Opus 4.6: ~1500ms
– Gemini 3.1 Pro: ~800ms
Step 5: Evaluate Ecosystem Fit
Your existing stack matters:
– Already using OpenAI? Stick with GPT-5.4 unless cost forces a change
– Google Cloud shop? Gemini 3.1 Pro integrates seamlessly
– AWS environment? Consider Claude via Bedrock
– Need European residency? Mistral is your answer
– Building AI agents? Claude Sonnet 4.6 has the best tooling
Common Mistakes to Avoid
Mistake #1: Defaulting to GPT-5.4
GPT-5.4 is excellent but overkill for many tasks. A classification job that works fine with GPT-5 nano ($0.05/M) doesn’t need GPT-5.4 ($2.50/M). That’s a 50x cost difference.
Mistake #2: Ignoring Output Costs
Output tokens often cost 4-6x more than input tokens. A chatbot that generates long responses spends more on output than input. Model choice affects this dramatically—Claude Opus charges $75/M output vs Gemini 3.1 Pro’s $5/M.
Mistake #3: Overlooking Context Windows
Processing a 100-page document in 4K chunks requires 25 API calls. In a 1M context window, it’s one call. The math favors larger windows for document-heavy workloads.
Mistake #4: Not Implementing Caching
OpenAI and Anthropic both offer prompt caching discounts. Cached inputs cost 50-90% less. If you’re processing similar documents or repeated queries, caching cuts costs significantly.
Mistake #5: Choosing Based on Hype
Grok’s real-time data is cool. Claude Opus’s reasoning is impressive. But if you’re building a customer support bot, you probably don’t need either. Match the tool to the task.
Implementation Tips
Start with a Model Router
Don’t hardcode one model. Build a router that sends simple tasks to cheap models and complex tasks to capable ones:
def route_request(task_complexity, input_tokens):
if task_complexity == "simple":
return "gpt-5-nano"
elif input_tokens > 100000:
return "gemini-3.1-pro"
else:
return "gpt-5.4"Implement Token Budgets
Set per-request and per-user limits:
MAX_TOKENS_PER_REQUEST = 4000
MAX_COST_PER_USER_PER_DAY = 5.00 # dollarsMonitor and Optimize
Track these metrics:
– Cost per request
– Tokens per request (input/output split)
– Latency by model
– Error rates
– User satisfaction scores
Use this data to optimize your routing logic monthly.
The Bottom Line
The “best” LLM API depends on your specific needs:
– Best overall value: Gemini 3.1 Pro (94 score, half the price of GPT-5.4)
– Safest choice: GPT-5.4 (proven, well-supported, excellent quality)
– Best for coding: Claude Sonnet 4.6 (85+ on coding benchmarks)
– Cheapest viable option: DeepSeek V3 (72 score at $0.27/M)
– Best free tier: Gemini 3.1 Flash-Lite (1M context for $0.10/M)
The LLM API market in 2026 is a buyer’s market. You have genuine alternatives to OpenAI. Gemini 3.1 Pro matches GPT-5.4’s quality at half the price. DeepSeek V3 delivers usable quality at a fraction of the cost. Claude Sonnet 4.6 dominates coding tasks.
Your job isn’t to pick the best model. It’s to pick the right model for each task—and build systems that route requests intelligently.
FAQ
Q: Can I switch between models easily?
Most providers use similar API structures. OpenAI’s SDK has become the de facto standard. Anthropic, Google, and others offer OpenAI-compatible endpoints. Expect 1-2 days of integration work per model switch.
Q: How accurate are these benchmark scores?
Benchmarks measure specific capabilities, not overall “intelligence.” A model with a 94 score isn’t “94% good”—it scored 94 on a specific evaluation suite. Always test with your actual use cases.
Q: Should I use multiple models or standardize on one?
Hybrid approaches are becoming standard. Use cheap models for preprocessing and routing, expensive models for complex tasks. This cuts costs 60-80% versus using GPT-5.4 for everything.
Q: What about on-premise or self-hosted models?
Llama 3, Mistral, and other open models can run locally. Costs shift from API calls to infrastructure. Break-even typically happens at 10M+ tokens/month. Below that, APIs are cheaper.
Q: How do I handle rate limits?
Implement exponential backoff. Cache aggressively. Use multiple providers as fallbacks. Most production applications need at least two model providers for reliability.
Q: Are there hidden costs?
Watch for:
– Tokenization differences (same text = different token counts)
– Context caching fees
– Fine-tuning costs
– Data transfer charges
– Support plan requirements
Key Takeaways
1. Gemini 3.1 Pro offers the best value—94 score at $1.25/M input, half GPT-5.4’s price
2. GPT-5.4 remains the safe default—proven, well-supported, excellent quality
3. Claude Sonnet 4.6 dominates coding—85+ on coding benchmarks, 200K context
4. DeepSeek V3 is the budget champion—72 score at $0.27/M, 9x cheaper than GPT-5.4
5. Match model to task—using GPT-5.4 for simple classification wastes 50x the cost
6. Output costs matter—they’re often 4-6x higher than input costs
7. Context windows vary dramatically—32K to 1M tokens changes architecture decisions
8. Implement model routing—save 60-80% by routing simple tasks to cheap models
9. European alternatives exist—Mistral Large 3 for GDPR compliance
10. Test with your data—benchmarks guide, but your use case decides
Ready to integrate AI into your SaaS? [Fungies.io](https://app.fungies.io/register) handles payments, tax compliance, and checkout—so you can focus on building great AI-powered features.
References
– [BenchLM.ai LLM Pricing Comparison 2026](https://benchlm.ai/blog/posts/llm-pricing-2026)
– [TLDL.io AI Coding Tools Comparison](https://www.tldl.io/resources/ai-coding-tools-2026)
– [OpenAI API Pricing](https://openai.com/api/pricing)
– [Anthropic Claude Pricing](https://claude.com/pricing)
– [Google Gemini API Pricing](https://ai.google.dev/gemini-api/docs/pricing)
– [DeepSeek API Documentation](https://api-docs.deepseek.com/)
– [Mistral AI Pricing](https://mistral.ai/pricing)
– [xAI Grok Documentation](https://docs.x.ai/)