In June 2025, Andrej Karpathy posted something that shook the AI engineering community: “I really like the term ‘context engineering’ over prompt engineering.” The OpenAI co-founder and former Tesla AI director wasn’t just suggesting a rebrand. He was identifying a fundamental shift in how we work with large language models.
Here’s the reality: 57% of organizations now have AI agents in production, according to LangChain’s 2025 State of Agent Engineering report. Yet most failures don’t trace to model capabilities. They trace to poor context management. The developers who master context engineering in 2026 will build AI systems that actually work. Everyone else will keep wondering why their “perfectly good prompts” produce inconsistent garbage.
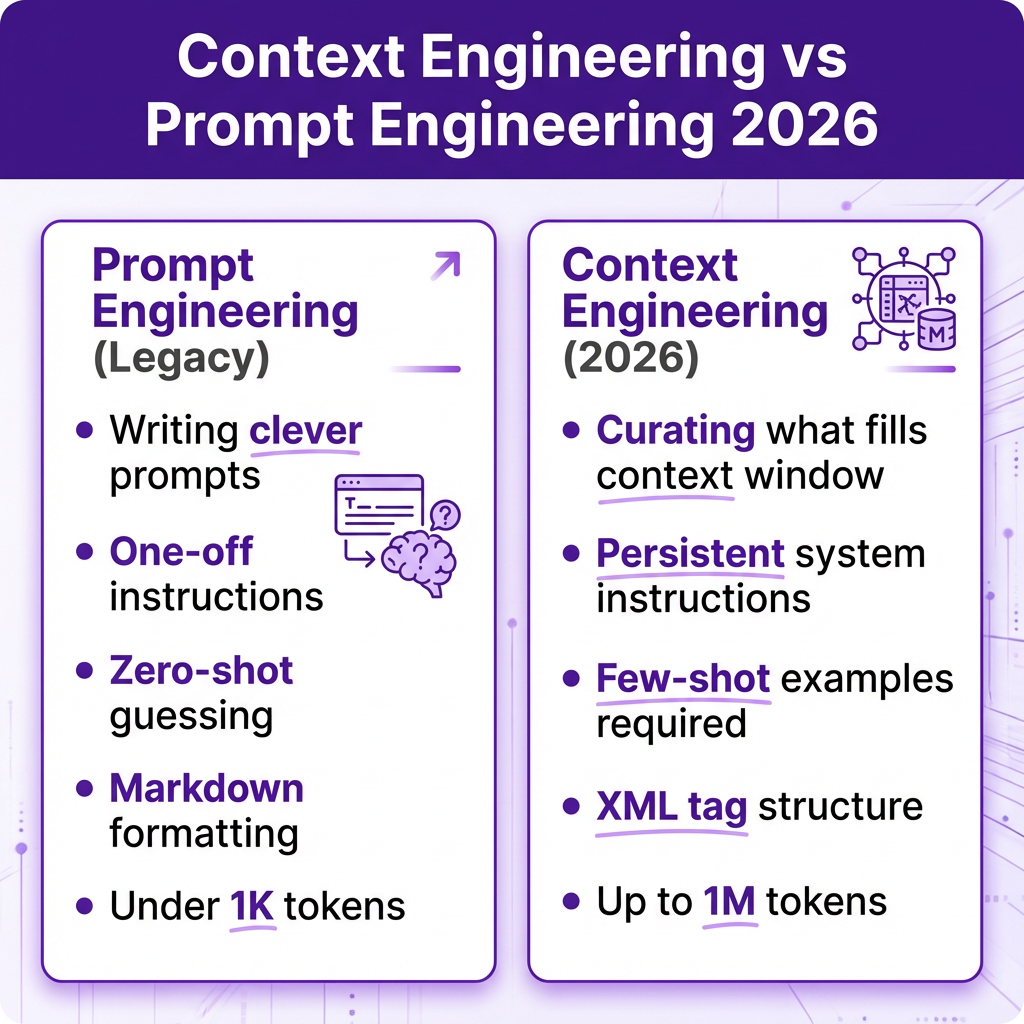
What Is Context Engineering (And Why Prompt Engineering Is Dead)
Prompt engineering was about writing clever instructions. Context engineering is about curating exactly what information fills the context window for each task. Think of the LLM as a CPU and the context window as RAM. You’re the operating system responsible for loading the right information.
The distinction matters because models have changed. GPT-5, Claude 4.6, and Gemini 2.5 Pro don’t need you to explain reasoning step-by-step. Their router architectures handle that internally. What they need is the right context to reason about.
Why “Think Step by Step” Now Hurts Your Results
Here’s a counterintuitive finding from 2026 research: explicit chain-of-thought instructions can actually degrade performance on reasoning models. GPT-5’s internal routing handles reasoning automatically. When you add “think step by step,” you’re either redundant or interfering.
Google’s December 2025 prompting whitepaper confirms this. Their recommendation: always include few-shot examples, but place specific questions at the end, after your data context. Zero-shot prompting is explicitly not preferred for production.
Even more surprising: long prompts degrade performance after roughly 3,000 tokens. Research from Wharton Generative AI Labs (June 2025) found that complex prompts filled with step-by-step rules cause “Prompting Inversion” — adverse effects on top-tier models. Sometimes less instruction produces better results.
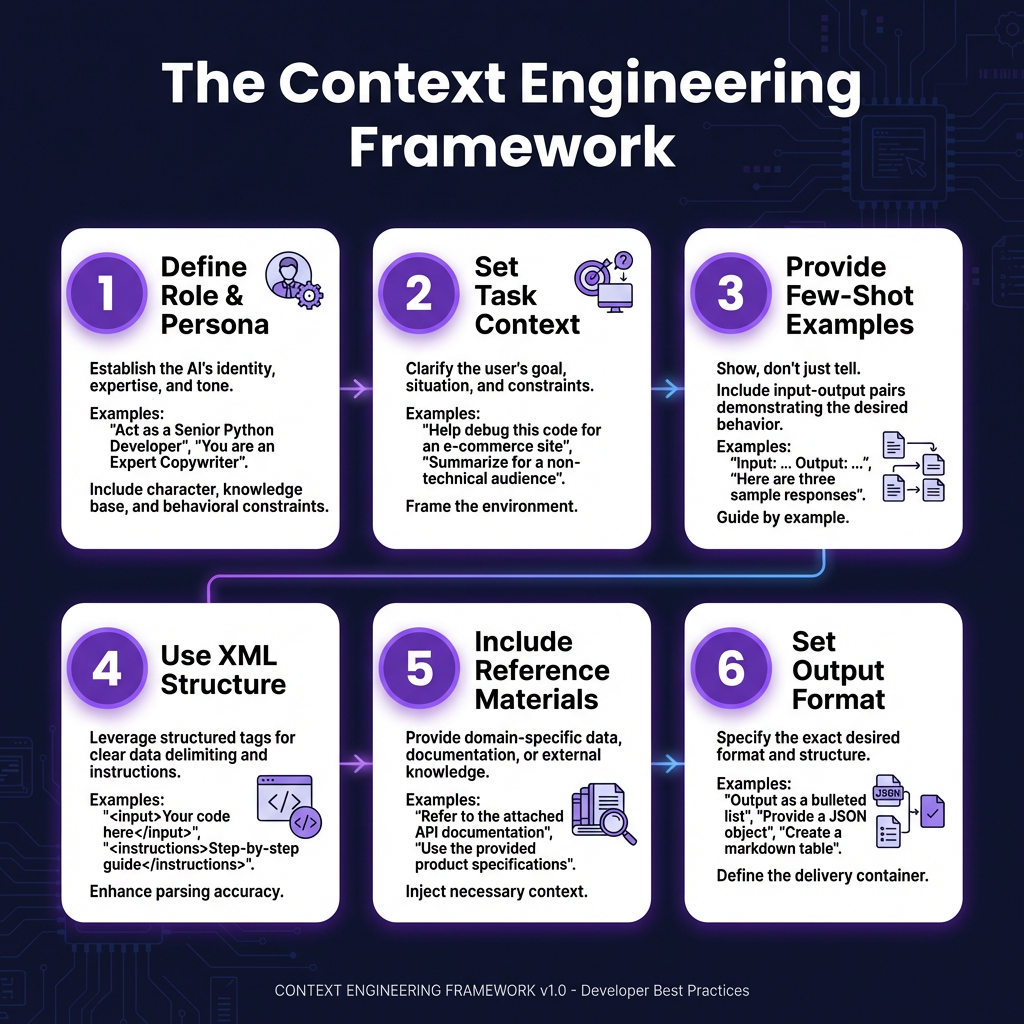
The 6 Components of Production-Grade Context
Every production context engineering setup needs these six components. Skip one and your system becomes brittle.
1. Role Definition and Persona
Define who the AI is. Not just “you are a helpful assistant.” Be specific: “You are a senior TypeScript developer with 10 years of experience building payment systems. You prioritize security, type safety, and clean error handling.”
The persona shapes tone, depth, and priorities. A “junior developer” persona gives different explanations than a “staff engineer” persona. Both are valid — pick intentionally.
2. Task Context and Constraints
What is this code supposed to do? What are the constraints? Include:
- Tech stack: TypeScript/Node.js/PostgreSQL
- This code handles: payments/user auth/data processing
- Team standards: link to style guide or paste key rules
- Performance requirements: latency budgets, throughput needs
- Security constraints: what data must never be logged
3. Few-Shot Examples (Required)
Zero-shot is for demos. Production requires examples. Show the model exactly what good output looks like. Include 2-3 examples covering different scenarios.
But watch out for the “Few-Shot Dilemma.” Research from September 2025 (arXiv:2509.13196) found that over-prompting with too many examples can hurt performance on large language models. The sweet spot is typically 2-4 examples, not 10.
4. XML Structure (Not Markdown)
Anthropic’s internal prompting uses XML tags, not Markdown. Claude recognizes XML natively and produces more structured outputs. Google Research found that XML tagging improves response quality by up to 30% on multi-document tasks.
<role> You are a senior code reviewer focused on security and performance. </role> <context> Tech stack: Python/FastAPI/PostgreSQL This service handles: user authentication </context> <code_to_review> [code here] </code_to_review> <review_format> For each issue: - Severity: [Critical/Major/Minor] - Location: [line or function] - Issue: [clear description] - Fix: [suggested code] </review_format>
5. Reference Materials
Include relevant documentation, API schemas, database schemas, or previous similar implementations. With 1M-token context windows (Claude 3.7, Gemini 2.5), you can include entire codebases or documentation sets.
This is where RAG (Retrieval-Augmented Generation) becomes critical. Don’t dump everything into context. Retrieve exactly what’s relevant. Top RAG frameworks in 2026 include LangChain, LlamaIndex, and Haystack — each optimized for different use cases.
6. Output Format Specification
Be explicit about format. JSON? Markdown? Specific field names? If you need structured output, provide a schema or example.
Context Engineering in Practice: A Complete Example
Here’s a production-ready context engineering template for code review:
<system_context>
You are a senior TypeScript engineer reviewing code for a fintech application.
Security and type safety are paramount. Be direct and specific.
</system_context>
<project_context>
- Framework: Next.js 14 with App Router
- Database: PostgreSQL via Prisma ORM
- Auth: NextAuth.js with JWT sessions
- This module: Payment processing webhook handler
</project_context>
<standards>
- All database queries must use parameterized statements
- Never log PII or payment card data
- All async operations need explicit error handling
- Prefer explicit types over inference for function signatures
</standards>
<example_review>
<issue>
<severity>Critical</severity>
<location>processPayment() line 23</location>
<problem>Raw SQL concatenation without parameterization</problem>
<fix>
// Before:
await db.query(`SELECT * FROM payments WHERE id = ${paymentId}`)
// After:
await db.query('SELECT * FROM payments WHERE id = $1', [paymentId])
</fix>
</issue>
</example_review>
<code_to_review>
[paste code here]
</code_to_review>
<output_instructions>
List all issues found. For each:
1. Severity (Critical/Major/Minor)
2. Exact location
3. Clear problem description
4. Specific fix with code
If no issues found, state "No issues detected" and explain why the code meets standards.
</output_instructions>
Advanced Techniques: ReAct, CoT, and Tree-of-Thought
For complex reasoning tasks, structure your context to support advanced frameworks:
ReAct (Reasoning + Acting)
ReAct combines reasoning traces with actions. The LLM thinks through a problem, takes an action (like calling a tool), observes the result, and continues reasoning. This loop continues until the task completes.
Research shows ReAct generally outperforms action-only approaches on knowledge-intensive tasks. The key is structuring your context to support the reasoning-observation loop.
Tree-of-Thought (ToT)
For problems requiring exploration of multiple paths, Tree-of-Thought prompts the model to generate multiple reasoning paths, evaluate each, and select the most promising. This is particularly effective for coding problems with multiple valid approaches.
Dynamic Recursive Chain-of-Thought (DR-CoT)
A 2025 paper in Scientific Reports introduced DR-CoT, which adds meta-reasoning to chain-of-thought. The model not only reasons step-by-step but evaluates whether it needs to backtrack or explore alternative paths.
Context Engineering for Different Model Families
Each model family has different context engineering preferences:
| Model Family | Best Format | Context Window | Key Preference |
|---|---|---|---|
| Claude (Anthropic) | XML tags | 200K-1M tokens | Structured, explicit constraints |
| GPT-5 (OpenAI) | Markdown + clear sections | 128K-2M tokens | Examples at end, minimal CoT |
| Gemini (Google) | Structured markdown | 1M+ tokens | Long context, multimodal |
| DeepSeek | Clear instructions | 64K-128K tokens | Direct, minimal fluff |
Version Control Your Prompts
Context engineering artifacts are code. Treat them like it:
- Store system prompts in version control
- Document what each prompt does — input, output, when to use it
- Test prompts regularly — models change, prompts drift
- Use A/B testing for prompt variations
- Monitor token usage and latency
Build a prompt library. Document the purpose, expected inputs, and output format for each context template. Your future self (and teammates) will thank you.
Common Context Engineering Mistakes
Watch out for these pitfalls:
1. Context Rot
Your reference materials get stale. Database schemas change. API versions update. Set up processes to refresh context regularly.
2. Over-Prompting
More instructions don’t always help. The September 2025 research on over-prompting shows that excessive constraints can confuse models. Be precise, not verbose.
3. Ignoring Token Economics
Long contexts cost more and increase latency. With GPT-5 at $10/$30 per million tokens, a 10K token context used in 10,000 daily conversations costs $49,500 monthly. Optimize ruthlessly.
4. Static Context
Don’t use the same context for every request. Dynamically retrieve and inject relevant information based on the specific task.
Key Takeaways
Context engineering is the skill that separates working AI systems from demoware. Here’s what to remember:
- Prompt engineering is dead. Context engineering is what matters now.
- “Think step by step” hurts reasoning models. Let GPT-5 and Claude 4.6 handle reasoning internally.
- Use XML tags, not Markdown. Especially for Claude — 30% improvement in structured tasks.
- Always include few-shot examples. Zero-shot is for demos, not production.
- Keep prompts under 3,000 tokens when possible. Performance degrades with excessive length.
- Version control your prompts. They’re code. Treat them like it.
FAQ
What’s the difference between prompt engineering and context engineering?
Prompt engineering focuses on writing clever instructions. Context engineering focuses on curating exactly what information fills the context window — role definitions, examples, reference materials, and output formats. It’s a broader, more systematic approach.
Do I still need to learn prompt engineering techniques?
The fundamentals still apply, but the focus has shifted. Understanding zero-shot, few-shot, and chain-of-thought is useful, but applying them within a context engineering framework is what produces production results.
Which models benefit most from context engineering?
All modern models (GPT-5, Claude 4.6, Gemini 2.5) benefit, but the techniques vary. Claude responds best to XML structure. GPT-5 prefers examples at the end with minimal explicit reasoning instructions. Gemini handles very long contexts well.
How do I measure context engineering effectiveness?
Track output quality (human evaluation or automated metrics), token usage, latency, and consistency across runs. A/B test different context structures to find what works for your specific use case.
Can context engineering replace fine-tuning?
For many use cases, yes. With 1M-token context windows and good context engineering, you can often achieve results comparable to fine-tuning without the infrastructure overhead. Fine-tuning is still valuable for specific style requirements or when latency is critical.
Conclusion
We’re past the era of clever prompt tricks. The developers who thrive in 2026 will be those who treat context engineering as a core skill — designing systems that feed the right information to AI models at the right time.
Start by auditing your current prompts. Are you using XML structure? Do you have version control? Are you including few-shot examples? Are your reference materials current? Fix those fundamentals, and you’ll be ahead of 90% of teams building with AI.
Ready to build AI-powered features into your application? Get started with Fungies.io — we handle the payments and tax complexity so you can focus on shipping AI features your users will love.
References
- Karpathy, A. (2025). “Context engineering over prompt engineering.” X/Twitter. https://x.com/karpathy/status/1937902205765607626
- LangChain (2025). State of Agent Engineering Report. https://langchain.com/state-of-agent-engineering
- Google Research (2025). Prompt Engineering Whitepaper. https://www.kaggle.com/whitepaper-prompt-engineering
- Wharton Generative AI Labs (2025). “The Decreasing Value of Chain of Thought in Prompting.” arXiv:2506.07142
- arXiv (2025). “The Few-Shot Dilemma: Over-prompting Large Language Models.” arXiv:2509.13196
- Scientific Reports/Nature (2025). “DR-CoT: Dynamic Recursive Chain of Thought with Meta Reasoning.”
- Google Research (2025). “Prompt Repetition Improves Non-Reasoning LLMs.” arXiv:2512.14982
- Anthropic (2026). Claude Documentation: Use XML Tags. https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/use-xml-tags
- Redwerk (2026). RAG Best Practices. https://redwerk.com/blog/rag-best-practices/
- Tredence (2026). Top 5 RAG Frameworks for 2026. https://www.tredence.com/blog/top-rag-frameworks