Here’s a number that should get your attention: pricing varies by more than 600x across major LLM APIs — from $0.05 to $30 per million input tokens. If you’re building AI-powered features in 2026 and not actively optimizing your model selection, you’re literally burning money.
I’ve spent the last month analyzing pricing from OpenAI, Anthropic, Google, DeepSeek, and xAI. The differences aren’t marginal — they’re massive. A request that costs $0.0001 on Gemini Flash runs $0.10+ on GPT-5.2 Pro. At scale, that gap becomes a $100,000+ annual difference.
This guide breaks down exactly what every major LLM API costs in 2026, when to use each tier, and how to build a cost-optimized AI stack that doesn’t sacrifice quality.

What Is LLM API Pricing and Why It Matters in 2026
LLM APIs charge by the token — roughly 4 characters or 0.75 words per token. Most providers bill separately for input (what you send) and output (what the model returns). Output tokens typically cost 2-5x more than input tokens.
In 2026, this pricing model has become a strategic consideration. With AI features moving from experiments to core product functionality, token costs now show up as line items on P&L statements. Teams that understand the pricing landscape gain a competitive advantage — they can offer AI features at lower prices or higher margins than competitors using the wrong models.
Complete LLM API Pricing Comparison 2026
Here’s the current pricing for every major model as of April 2026. All prices are per million tokens:
| Model | Provider | Input | Output | Quality Score |
|---|---|---|---|---|
| GPT-5 nano | OpenAI | $0.05 | $0.40 | — |
| Gemini 3.1 Flash-Lite | $0.10 | $0.40 | — | |
| DeepSeek V3.2 | DeepSeek | $0.26 | $0.38 | 79 |
| Grok 3 Mini | xAI | $0.30 | $0.50 | — |
| Gemini 3.1 Pro | $1.25 | $5.00 | 94 | |
| GPT-5.1 | OpenAI | $1.50 | $10.00 | 91 |
| GPT-5.4 | OpenAI | $2.50 | $15.00 | 94 |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 | 68 |
| Grok 4.1 | xAI | $3.00 | $15.00 | 76 |
| Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | 85 |
| GPT-5.2 Pro | OpenAI | $25.00 | $150.00 | 66 |
| GPT-5.4 Pro | OpenAI | $30.00 | $180.00 | 91 |
Source: CostGoat, BenchLM.ai — Quality scores based on independent Theozard benchmarks
The Three Cost Tiers Explained
Tier 1: Budget Models (Under $0.50/M Input)
Models: GPT-5 nano ($0.05), Gemini 3.1 Flash-Lite ($0.10), DeepSeek V3.2 ($0.26), Grok 3 Mini ($0.30)
Best for: High-volume, lower-stakes tasks — classification, summarization, simple Q&A, content filtering.
The catch: Quality varies significantly. GPT-5 nano is 600x cheaper than GPT-5.4 Pro, but it’s not suitable for complex reasoning or creative tasks. Use these for pre-processing, routing decisions, or any task where “good enough” is actually good enough.
Tier 2: Production Sweet Spot ($1-3/M Input)
Models: Gemini 3.1 Pro ($1.25), GPT-5.1 ($1.50), GPT-5.4 ($2.50), Claude Sonnet 4.6 ($3.00), Grok 4.1 ($3.00)
Best for: Production workloads where quality matters but cost can’t spiral — customer support chatbots, content generation, code completion, most SaaS AI features.
The standout: Gemini 3.1 Pro at $1.25/$5 scores 94 on quality benchmarks — tied with GPT-5.4 at $2.50/$15 — while costing exactly half as much. For many teams, this is now the clearest value play in the frontier tier.
Tier 3: Flagship Tier ($15-30/M Input)
Models: Claude Opus 4.6 ($5/$25), GPT-5.2 Pro ($25/$150), GPT-5.4 Pro ($30/$180)
Best for: Tasks where capability is worth any price — legal analysis, complex research, high-stakes decisions, agentic coding workflows that require deep reasoning.
The reality check: Most teams overuse flagship models. If you’re not doing multi-step reasoning or generating high-stakes content, you’re probably paying 10x more than necessary.
Real-World Cost Calculations by Use Case
Use Case 1: Customer Support Chatbot
Assume 10,000 conversations/month, averaging 500 input tokens and 200 output tokens each:
| Model | Monthly Cost |
|---|---|
| Gemini 3.1 Flash-Lite | $1.30 |
| DeepSeek V3.2 | $1.38 |
| Gemini 3.1 Pro | $11.25 |
| GPT-5.4 | $15.50 |
| Claude Sonnet 4.6 | $18.00 |
| Claude Opus 4.6 | $30.00 |
Recommendation: For most support chatbots, Gemini 3.1 Pro hits the sweet spot — capable enough to handle complex queries, cheap enough to scale. Only upgrade to Claude Opus if you’re doing technical support requiring deep reasoning.
Use Case 2: Document Processing Pipeline
Processing 1,000 documents/day (10 pages each ≈ 4,000 input tokens, 500 output tokens):
| Model | Cost per Document | Monthly Cost |
|---|---|---|
| Gemini 3.1 Flash-Lite | $0.0006 | $18 |
| DeepSeek V3.2 | $0.0014 | $42 |
| Gemini 3.1 Pro | $0.0053 | $159 |
| GPT-5.4 | $0.0175 | $525 |
| Claude Opus 4.6 | $0.098 | $2,940 |
Recommendation: At document scale, model selection has direct P&L impact. Gemini 3.1 Pro vs Claude Opus is an 18x cost difference. Use tier 1 models for initial classification and extraction, tier 2 for synthesis and analysis.
Use Case 3: AI Coding Assistant
For an IDE integration handling 100K suggestions/day (avg 100 input, 50 output tokens):
| Model | Daily Cost | Monthly Cost |
|---|---|---|
| GPT-5.4 | $35 | $1,050 |
| Claude Sonnet 4.6 | $37.50 | $1,125 |
| Gemini 3.1 Pro | $17.50 | $525 |
| Claude Opus 4.6 | $62.50 | $1,875 |
Recommendation: For autocomplete and short completions, GPT-5.4 or Gemini 3.1 Pro are nearly indistinguishable from flagships. Reserve Claude Opus for code review, refactoring, and complex agentic workflows.
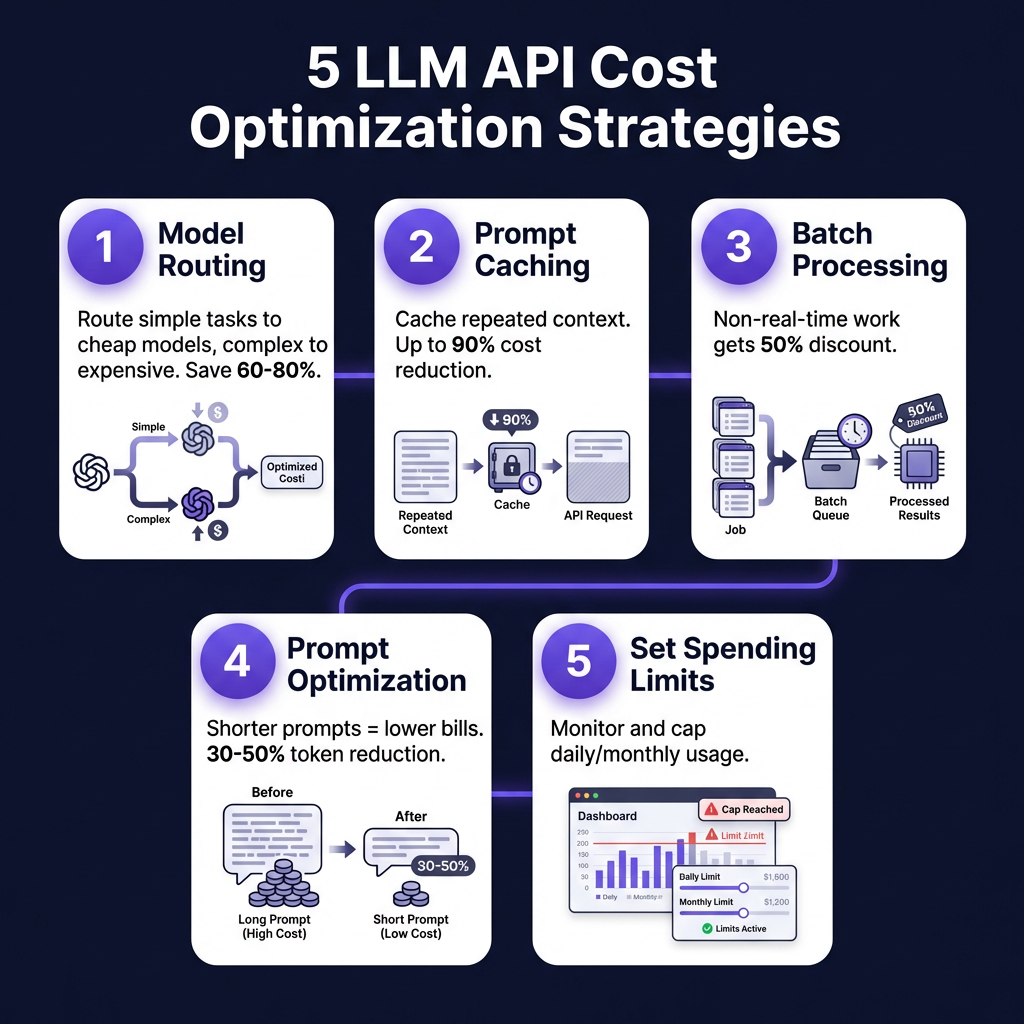
5 Cost Optimization Strategies That Actually Work
1. Implement Model Routing
Don’t use one model for everything. Build a routing layer that sends simple tasks to cheap models and complex tasks to expensive ones. A hybrid “Router” strategy — sending 80% of routine traffic to budget models while reserving frontier models for high-stakes reasoning — typically cuts costs by 60-80% without quality loss.
2. Use Caching Aggressively
OpenAI and Anthropic both offer prompt caching that reduces input costs by up to 90% for repeated context. If you’re sending similar system prompts or context windows repeatedly, caching is non-negotiable.
3. Batch Non-Real-Time Workloads
Most providers offer 50% discounts for batch processing. If you’re generating reports, processing documents, or doing any work that doesn’t need instant response, batching cuts costs in half.
4. Optimize Your Prompts
Every token you send costs money. Shorter prompts = lower bills. Remove fluff, use concise examples, and avoid repeating instructions. A well-engineered prompt can often achieve the same result with 30-50% fewer tokens.
5. Monitor and Set Limits
Token costs can spiral unexpectedly. Set daily/monthly spend caps, monitor per-request costs, and alert when spending exceeds projections. Most cost overruns happen because teams aren’t watching.
Provider-Specific Pricing Quirks
OpenAI
- Most complex pricing structure with “Pro” variants at 10x cost
- Offers cached input pricing (50% discount)
- Batch API available at 50% discount
- GPT-5 nano is the cheapest major LLM API at $0.05/M tokens
Anthropic
- Simpler tier structure: Haiku/Sonnet/Opus
- Claude Opus 4.6 offers best-in-class reasoning but at premium pricing
- Prompt caching reduces costs significantly for repeated context
- Most aggressive pricing on frontier models
- Gemini 3.1 Pro delivers GPT-5.4 quality at half the price
- Flash-Lite models are unbeatable for high-volume, low-complexity tasks
DeepSeek
- Consistently the cheapest high-quality option
- DeepSeek V3.2 at $0.26/$0.38 delivers quality scores rivaling much more expensive models
- Output tokens are 100x cheaper than GPT-5.4 Pro
Key Takeaways: Building Your Cost-Optimized AI Stack
After analyzing 300+ models and real-world usage patterns, here’s what actually matters:
- Start with Gemini 3.1 Pro for most production workloads — it’s the current value champion at 94 quality for $1.25/$5
- Use DeepSeek V3.2 for high-volume, cost-sensitive tasks — $0.26/$0.38 with quality scores in the high 70s
- Reserve Claude Opus 4.6 only for tasks requiring the absolute best reasoning capabilities
- Implement model routing — the teams saving 60-80% on AI costs all use some form of intelligent routing
- Monitor relentlessly — token costs scale linearly with usage, and surprises show up on your bill, not your dashboard
The LLM API pricing landscape in 2026 rewards informed decision-making. The difference between using the right model and the default model isn’t 10% — it’s often 10x. Choose wisely.
Frequently Asked Questions
What is the cheapest LLM API in 2026?
GPT-5 nano from OpenAI is the cheapest major LLM API at $0.05 per million input tokens. However, for production use, DeepSeek V3.2 at $0.26/$0.38 offers the best balance of cost and quality, delivering benchmark scores in the high 70s.
How much does GPT-5.4 cost per API call?
GPT-5.4 costs $2.50 per million input tokens and $15 per million output tokens. A typical API call with 500 input tokens and 200 output tokens costs approximately $0.00425. At scale (1M calls/month), expect to spend around $4,250.
Is Claude or GPT-5 cheaper?
It depends on the tier. Claude Sonnet 4.6 ($3/$15) is slightly more expensive than GPT-5.4 ($2.50/$15). However, Claude Opus 4.6 ($5/$25) is significantly cheaper than GPT-5.4 Pro ($30/$180). For most production workloads, GPT-5.4 and Claude Sonnet are roughly comparable in price.
How can I reduce my LLM API costs?
The most effective strategies are: (1) Implement model routing to use cheaper models for simple tasks, (2) Use prompt caching for repeated context (up to 90% savings), (3) Batch non-real-time workloads for 50% discounts, (4) Optimize prompts to reduce token count, and (5) Set spending limits and monitor usage closely.
Which LLM API offers the best value in 2026?
Based on quality-per-dollar metrics, Gemini 3.1 Pro currently offers the best value — it scores 94 on quality benchmarks (tied with GPT-5.4) while costing half the price at $1.25/$5 per million tokens. For pure cost efficiency, DeepSeek V3.2 delivers the highest value score at 207.9.
Conclusion
LLM API pricing in 2026 is a strategic weapon. The teams that understand the landscape — that know when to use GPT-5 nano versus Claude Opus — will build AI features at a fraction of the cost of their competitors. The 600x price difference between budget and flagship models isn’t a bug; it’s an opportunity for smart engineering.
If you’re building AI-powered SaaS features, start with the cost optimization strategies in this guide. Your margins will thank you.
Ready to add AI-powered payments to your SaaS? Get started with Fungies.io — the merchant of record platform that handles global tax compliance, 50+ payment methods, and a developer-friendly API so you can focus on building, not billing infrastructure.




