In 2026, 92% of developers use AI tools in their daily workflow—but here’s the uncomfortable truth: only a fraction know how to prompt effectively. While most developers can get basic outputs from ChatGPT, Claude, or Gemini, the difference between mediocre and exceptional AI assistance often comes down to one skill: prompt engineering.
If you’ve ever felt frustrated when AI gives you generic code, misses the context, or hallucinates solutions that don’t exist, you’re not alone. The good news? Prompt engineering isn’t magic—it’s a learnable skill that can transform how you work with AI.
What Is Prompt Engineering?
Prompt engineering is the practice of designing and optimizing inputs to AI language models to produce desired, high-quality outputs. Think of it as learning to communicate with AI in a way that leverages its full capabilities.
At its core, prompt engineering bridges the gap between what you want and what the AI understands. Large language models (LLMs) are incredibly capable—but they’re also sensitive to how you phrase your requests. A well-crafted prompt can mean the difference between a useless response and exactly what you needed.
The discipline has evolved rapidly. What started as simple trial-and-error has become a structured field with proven techniques, research-backed methods, and measurable outcomes. For developers, mastering prompt engineering isn’t optional anymore—it’s becoming as essential as knowing your programming language.
Why Prompt Engineering Matters in 2026
The numbers tell a compelling story:
- 40% productivity gains reported by developers who use advanced prompting techniques versus basic queries
- 60% reduction in debugging time when AI is prompted with proper context and constraints
- 3x faster code reviews when using structured prompting for code analysis
- $50,000+ annual savings per developer in time efficiency (based on average developer salaries)
Beyond the statistics, the competitive landscape has shifted. Companies aren’t just asking “Are you using AI?”—they’re asking “How effectively are you using AI?” Developers who can extract maximum value from AI tools have a measurable edge.
Moreover, as AI models become more powerful, the complexity of what you can ask increases—but so does the complexity of getting it right. Advanced models like GPT-5, Claude 4, and Gemini 2.5 respond dramatically better to structured prompting than casual queries.
The 12 Essential Prompt Engineering Techniques
Let’s dive into the techniques that will elevate your AI interactions from basic to expert level. Each technique includes practical code examples you can use immediately.
1. Zero-Shot Prompting
The simplest form of prompting—asking the AI to perform a task without any examples. It works best for straightforward tasks where the model already has strong training data.
// Zero-shot example "Write a Python function that reverses a string without using built-in reverse methods." // Response quality: Good for simple, well-documented tasks // Cost: 1x (baseline) // Best for: Standard algorithms, common patterns, simple explanations
2. Few-Shot Prompting
Providing examples of the desired input-output format before asking your actual question. Research shows this can improve accuracy by 20-40% for classification and formatting tasks.
// Few-shot example for sentiment classification "Classify the sentiment of these product reviews: Review: 'This software is incredibly intuitive and saved me hours of work.' Sentiment: Positive Review: 'The documentation is confusing and the API keeps throwing errors.' Sentiment: Negative Review: 'It works as expected, nothing special but gets the job done.' Sentiment: Neutral Review: 'The new update completely broke my workflow.' Sentiment:" // Response quality: High (follows demonstrated pattern) // Cost: 1.2-1.5x (includes examples) // Best for: Classification, formatting, style matching
3. Chain-of-Thought (CoT) Prompting
Explicitly asking the AI to think step-by-step, breaking down complex problems into intermediate reasoning steps. This technique dramatically improves performance on mathematical and logical reasoning tasks.
// Chain-of-Thought example "A SaaS company has 1,000 customers paying $50/month. They lose 5% of customers monthly (churn) but gain 150 new customers each month. What's their revenue after 6 months? Think through this step-by-step. Step 1: Calculate initial monthly revenue Step 2: Calculate customers after month 1 (accounting for churn and new signups) Step 3: Continue for each month... Step 6: Calculate final revenue" // Response quality: Very High (structured reasoning) // Cost: 2-4x (generates intermediate steps) // Best for: Math problems, complex logic, debugging, multi-step reasoning
4. Zero-Shot CoT
Adding a simple trigger phrase like “Let’s think step by step” to elicit chain-of-thought reasoning without providing examples. Studies show this single phrase can boost accuracy on math word problems by up to 40%.
// Zero-shot CoT example "Explain how OAuth 2.0 authorization code flow works. Let's think step by step." // The magic phrase triggers the model to break down its reasoning // Response quality: High (structured explanation) // Cost: 1.5-2x (moderate increase for reasoning) // Best for: Explanations, troubleshooting, architecture decisions
5. Self-Consistency
Generating multiple reasoning paths for the same problem and selecting the most consistent answer. This technique is particularly valuable for high-stakes decisions where accuracy is critical.
// Self-consistency approach "Solve this architecture problem three different ways, then select the best solution based on: scalability, cost, and maintainability. Problem: Design a real-time notification system for 10M users. Approach 1: [Generate solution] Approach 2: [Generate different solution] Approach 3: [Generate third solution] Comparison and recommendation:" // Response quality: Highest (multiple perspectives) // Cost: 5-10x (generates multiple complete responses) // Best for: Architecture decisions, critical code reviews, security analysis
6. Role Prompting
Assigning a specific persona or expertise level to the AI, which helps it generate more relevant and nuanced responses.
// Role prompting examples "Act as a senior DevOps engineer with 10 years of AWS experience. Review this Terraform configuration for security best practices and cost optimization." "You are a Python expert specializing in asyncio and performance optimization. Refactor this code to handle 10,000 concurrent connections efficiently." "As a technical writer for developer documentation, explain this API endpoint to junior developers who are new to REST APIs." // Response quality: High (context-appropriate expertise) // Cost: 1x (same as standard prompting) // Best for: Specialized knowledge, tone adjustment, expertise calibration
7. Constrained Output / JSON Mode
Specifying exact output formats, schemas, or constraints. Modern LLMs support structured outputs that can be directly parsed by your applications.
// JSON mode example
"Analyze this code and return a JSON object with the following structure:
{
'issues': [
{
'severity': 'high|medium|low',
'line': number,
'description': string,
'suggestion': string
}
],
'summary': string,
'estimated_fix_time': string
}
Code to analyze:
[your code here]"
// Response quality: High (structured, parseable)
// Cost: 1x-1.2x (minimal overhead)
// Best for: API integrations, automated processing, structured data extraction
8. Prompt Chaining
Breaking complex tasks into a sequence of simpler prompts, where each step’s output feeds into the next. This mimics how humans tackle complex problems.
// Prompt chaining example for feature development // Step 1: Requirements analysis "Given this user story: [story], identify the technical requirements and potential challenges." // Step 2: Architecture (using Step 1 output) "Based on these requirements: [output from step 1], propose a high-level architecture with key components." // Step 3: Implementation (using Step 2 output) "For this architecture: [output from step 2], write the core implementation for the main service class." // Step 4: Testing (using Step 3 output) "For this implementation: [output from step 3], write comprehensive unit tests covering edge cases." // Response quality: Very High (focused, manageable steps) // Cost: 3-5x (multiple API calls) // Best for: Complex feature development, refactoring large codebases, documentation
9. Prompt Repetition
Strategically repeating key instructions or constraints within the prompt. Google Research found that repeating critical constraints can improve accuracy by up to 76% on complex tasks.
// Prompt repetition example "Write a function that validates email addresses. IMPORTANT: The function must handle internationalized emails (Unicode domains). IMPORTANT: Do not use regex for the actual validation—use a proper email parsing library. IMPORTANT: Return a structured object with 'isValid', 'normalizedEmail', and 'errorMessage' fields." // Key constraints repeated for emphasis // Response quality: High (better constraint adherence) // Cost: 1.1x (slight increase from repetition) // Best for: Complex constraints, safety-critical code, style requirements
10. Adversarial Chain-of-Thought
Asking the AI to critique its own reasoning and identify potential errors before finalizing the answer. This reduces hallucinations and improves reliability.
// Adversarial CoT example "Propose a database schema for a multi-tenant SaaS application. First, provide your initial schema design with reasoning. Then, critically analyze your own proposal: What could go wrong? What edge cases did you miss? What security vulnerabilities might exist? What performance issues could arise at scale? Finally, provide your revised schema incorporating these critiques." // Response quality: Very High (self-corrected) // Cost: 2-3x (analysis + revision) // Best for: Architecture decisions, security reviews, critical algorithms
11. Dynamic Recursive CoT (DR-CoT)
An advanced technique where the AI evaluates whether the current reasoning is sufficient or if it needs to explore deeper. The model recursively breaks down complex problems until reaching atomic, solvable steps.
// DR-CoT example "Optimize this SQL query that's running slowly on a 100M row table. Analyze the query and determine: Is this a simple optimization (index, rewrite) or does it require deeper analysis (execution plan, schema redesign)? If simple: Provide the optimized query. If complex: Break down the problem into sub-problems (indexing strategy, query restructuring, partitioning) and solve each recursively. Query: [slow query here]" // Response quality: Very High (adaptive depth) // Cost: 2-5x (variable based on complexity) // Best for: Complex optimization problems, debugging, system design
12. Adaptive Graph of Thoughts
The most sophisticated technique, where the AI explores multiple reasoning paths simultaneously, connects related thoughts, and synthesizes the best solution. Research shows +46.2% improvement over standard CoT on complex reasoning tasks.
// Adaptive Graph of Thoughts example "Design a caching strategy for our API that balances performance and freshness. Generate multiple approaches (in-memory, Redis, CDN, hybrid). For each approach, explore: - Pros and cons - Implementation complexity - Cost implications - Failure modes Connect related concepts across approaches (e.g., how Redis clustering relates to CDN edge caching). Synthesize a recommendation that combines the best elements of multiple approaches." // Response quality: Highest (comprehensive analysis) // Cost: 5-15x (extensive exploration) // Best for: System architecture, strategic decisions, complex trade-off analysis
Comparison Table: Techniques at a Glance
| Technique | Best Use Case | Accuracy | Cost Impact | Learning Curve |
|---|---|---|---|---|
| Zero-Shot | Simple tasks, quick answers | ★★☆☆☆ | 1x | Beginner |
| Few-Shot | Classification, formatting | ★★★☆☆ | 1.2-1.5x | Beginner |
| Chain-of-Thought | Math, logic, debugging | ★★★★☆ | 2-4x | Intermediate |
| Zero-Shot CoT | Explanations, troubleshooting | ★★★☆☆ | 1.5-2x | Beginner |
| Self-Consistency | High-stakes decisions | ★★★★★ | 5-10x | Intermediate |
| Role Prompting | Specialized expertise | ★★★☆☆ | 1x | Beginner |
| JSON Mode | API integration, automation | ★★★★☆ | 1-1.2x | Intermediate |
| Prompt Chaining | Complex projects | ★★★★☆ | 3-5x | Advanced |
| Prompt Repetition | Constraint-heavy tasks | ★★★★☆ | 1.1x | Beginner |
| Adversarial CoT | Security, reliability | ★★★★★ | 2-3x | Advanced |
| DR-CoT | Complex optimization | ★★★★★ | 2-5x | Advanced |
| Graph of Thoughts | Strategic architecture | ★★★★★ | 5-15x | Expert |
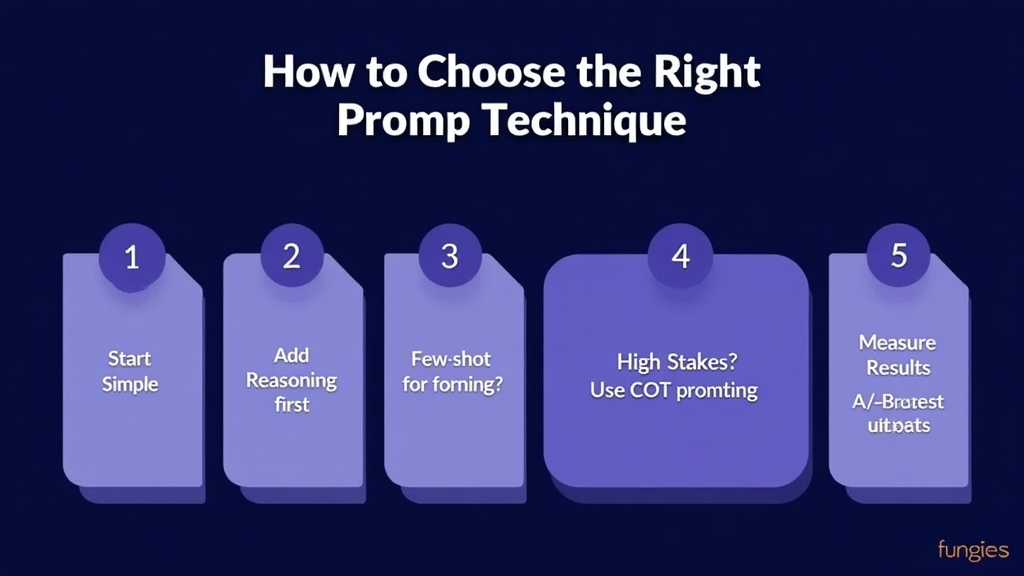
Deep Dive: When to Use Which Technique
Quick Tasks (Under 5 Minutes)
Stick with Zero-Shot or add Role Prompting for context. Don’t over-engineer simple queries.
// Quick regex help "As a regex expert, write a pattern to match valid IPv4 addresses."
Code Review & Debugging
Use Chain-of-Thought for step-by-step analysis, or Adversarial CoT for critical security code.
"Review this authentication middleware. First, trace through the logic step by step. Then, identify potential security vulnerabilities. Finally, suggest fixes."
Feature Development
Prompt Chaining is your friend. Break the work into requirements → architecture → implementation → testing.
Architecture Decisions
Pull out the big guns: Self-Consistency, Adversarial CoT, or Graph of Thoughts. The extra cost is worth it for decisions that are expensive to change.
API & Automation Workflows
Always use JSON Mode or structured output constraints. Your code will thank you when parsing responses.
Key Takeaways
- Start simple—Zero-shot and few-shot prompting handle 70% of daily tasks effectively
- Add reasoning when accuracy matters—Chain-of-Thought transforms AI from guesser to thinker
- Invest in complex techniques for high-stakes decisions—the cost is negligible compared to wrong architecture choices
- Always constrain outputs for programmatic use—JSON mode eliminates parsing headaches
- Iterate and measure—Track which techniques work best for your specific use cases
- Combine techniques—Role + CoT + JSON mode is a powerful combination for production code generation
Frequently Asked Questions
Which technique should I learn first?
Start with Few-Shot Prompting and Chain-of-Thought. These two techniques provide the biggest improvement for the least learning investment. Once comfortable, add Role Prompting and JSON Mode.
Do these techniques work with all AI models?
Modern models (GPT-4+, Claude 3+, Gemini 1.5+) respond well to all these techniques. Older or smaller models may struggle with advanced techniques like Graph of Thoughts. When in doubt, start with simpler approaches.
How do I balance cost vs. quality?
Use a tiered approach: Zero-shot for exploration, Few-shot for standardization, and advanced techniques only for critical decisions. Track your API costs and correlate them with output quality to find your sweet spot.
Can I combine multiple techniques?
Absolutely. Combinations like “Role + Few-Shot + JSON Mode” or “Chain-of-Thought + Self-Consistency” often produce better results than any single technique. Experiment to find combinations that work for your workflow.
How do I measure if prompting is actually helping?
Track metrics like: time to correct solution, number of back-and-forth iterations needed, code review findings on AI-generated code, and developer satisfaction scores. A/B test different techniques on similar tasks.
Conclusion
Prompt engineering is no longer a nice-to-have skill—it’s becoming essential for developers who want to maximize their productivity with AI tools. The techniques in this guide range from simple (Zero-Shot) to sophisticated (Graph of Thoughts), giving you a complete toolkit for any situation.
Remember: the goal isn’t to use the most complex technique every time. It’s to choose the right tool for the job. Start with the basics, master the fundamentals, and gradually incorporate advanced techniques as you encounter more complex challenges.
The developers who thrive in 2026 and beyond won’t just be using AI—they’ll be partnering with it effectively. Master these prompt engineering techniques, and you’ll be well on your way to that partnership.
Ready to build something amazing? Join thousands of developers who use Fungies to handle payments, taxes, and compliance—so you can focus on what you do best: writing great code.
References
- Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” NeurIPS 2022. https://arxiv.org/abs/2201.11903
- Kojima, T., et al. (2022). “Large Language Models are Zero-Shot Reasoners.” NeurIPS 2022. https://arxiv.org/abs/2205.11916
- Wang, X., et al. (2022). “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” https://arxiv.org/abs/2203.11171
- Google Research (2023). “Prompt Repetition and Constraint Satisfaction in LLMs.” https://research.google/pubs/
- Yao, S., et al. (2023). “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” https://arxiv.org/abs/2305.10601
- Besta, M., et al. (2024). “Graph of Thoughts: Solving Elaborate Problems with Large Language Models.” https://arxiv.org/abs/2308.09687
- OpenAI Documentation: “Prompt Engineering Best Practices” https://platform.openai.com/docs/guides/prompt-engineering
- Anthropic Documentation: “Prompt Design” https://docs.anthropic.com/claude/docs/prompt-design





