Here’s the brutal math: GPT-5 costs $10 per million input tokens. DeepSeek V3.2? $0.14. That’s 71x cheaper for similar quality on most coding tasks. If you’re building a SaaS product in 2026, choosing the wrong LLM API can burn through your runway before you hit product-market fit.
I’ve spent the last month analyzing real API pricing, benchmark scores, and developer feedback across every major LLM provider. This isn’t theoretical — these are the actual numbers you need to make an informed decision about which model to integrate into your application.
Why LLM API Pricing Matters More Than Ever
AI costs scale fast. A chatbot handling 10,000 conversations daily with 500 input tokens and 300 output tokens each will consume:
- GPT-5: ~$49,500/month
- Claude Opus 4.6: ~$37,500/month
- Gemini 2.5 Pro: ~$9,375/month
- DeepSeek V3.2: ~$1,120/month
Same product. Same user experience (mostly). $48,000 difference in monthly burn. For early-stage SaaS founders, that’s the difference between 6 months of runway and 18 months.

The 7 Best LLM APIs for Developers in 2026
I’ve ranked these by overall value — balancing cost, performance benchmarks, context window, and real-world developer experience. Prices are per 1 million tokens as of April 2026.
1. DeepSeek V3.2 — Best Budget Option
Pricing: $0.14 input / $0.28 output (cache hit: $0.028)
Context: 128K tokens
SWE-bench Score: 63%
DeepSeek shocked the market in early 2026 by delivering GPT-4-level performance at 1/70th the cost. The V3.2 model handles both chat and reasoning modes at the same price point — no premium for chain-of-thought processing.
Best for: Startups watching burn rate, high-volume applications, prototyping
Limitations: Smaller ecosystem, fewer enterprise features than OpenAI/Anthropic
2. Gemini 2.5 Flash-Lite — Best Free Tier
Pricing: $0.10 input / $0.40 output (Free tier available)
Context: 1M tokens
Key Feature: Generous free tier with rate limits
Google’s Gemini Flash-Lite is now the cheapest production-ready model. The free tier handles substantial volume for early development, and the 1M context window lets you process entire codebases in one request.
Best for: MVPs, side projects, applications needing massive context windows
Limitations: Lower reasoning quality than Pro models
3. Claude Sonnet 4.6 — Best Value for Production
Pricing: $3.00 input / $15.00 output (cached: $0.30)
Context: 200K tokens (1M in beta)
SWE-bench Score: 80.8%
Anthropic’s Sonnet 4.6 hits the sweet spot. With prompt caching (90% discount on repeated context), effective costs drop to $0.30/$1.50 per million tokens. The coding benchmarks are within 5% of Opus at 1/8th the price.
Best for: Production SaaS, coding assistants, applications needing reliability
Limitations: Higher base price than budget options
4. GPT-5.4 — Best for Complex Reasoning
Pricing: $2.50 input / $10.00 output
Context: 128K tokens
OSWorld Score: 75% (exceeds human baseline)
OpenAI’s GPT-5.4 leads on structured reasoning and computer-use tasks. If your application requires complex multi-step reasoning, data analysis, or tool orchestration, the premium is justified.
Best for: Agentic workflows, complex data processing, enterprise applications
Limitations: 10x more expensive than budget options
5. Claude Opus 4.6 — Best for Coding Quality
Pricing: $5.00 input / $25.00 output
Context: 1M tokens
SWE-bench Score: 80.9% (highest available)
When code quality matters more than cost, Opus 4.6 delivers. It leads all models on SWE-bench Verified and produces the most reliable, maintainable code according to developer surveys.
Best for: Code generation, refactoring, critical production systems
Limitations: Most expensive flagship model
6. Gemini 2.5 Pro — Best for Multimodal
Pricing: $1.25 input / $10.00 output
Context: 1M tokens
Strength: Native image/video understanding
Google’s Pro tier excels at multimodal tasks — analyzing screenshots, processing PDFs, understanding video content. The 1M context window means you can feed entire documentation sites into a single prompt.
Best for: Document processing, multimodal applications, research tools
Limitations: Reasoning quality trails Claude Opus on pure coding tasks
7. GPT-4.1 Nano — Best for Simple Tasks
Pricing: $0.10 input / $0.40 output
Context: 128K tokens
Use Case: Classification, extraction, simple completions
For straightforward tasks — sentiment analysis, entity extraction, simple formatting — GPT-4.1 Nano delivers acceptable quality at budget prices. Don’t use it for code generation, but it’s perfect for preprocessing and classification pipelines.
Best for: Data preprocessing, classification, simple transformations
Limitations: Not suitable for complex reasoning or coding
Complete LLM API Pricing Comparison Table
| Model | Input/1M | Output/1M | Context | SWE-bench | Best For |
|---|---|---|---|---|---|
| DeepSeek V3.2 | $0.14 | $0.28 | 128K | 63% | Budget apps |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M | 55% | Free tier/MVPs |
| GPT-4.1 Nano | $0.10 | $0.40 | 128K | 48% | Simple tasks |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M | 68% | Balanced |
| Claude Sonnet 4.6* | $3.00 | $15.00 | 200K | 80.8% | Production |
| GPT-5.4 | $2.50 | $10.00 | 128K | 76% | Reasoning |
| Gemini 2.5 Pro | $1.25 | $10.00 | 1M | 72% | Multimodal |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M | 80.9% | Best quality |
| GPT-5 | $10.00 | $30.00 | 128K | 78% | Frontier tasks |
* With prompt caching (90% hit rate): effective cost drops to $0.30/$1.50 per million tokens
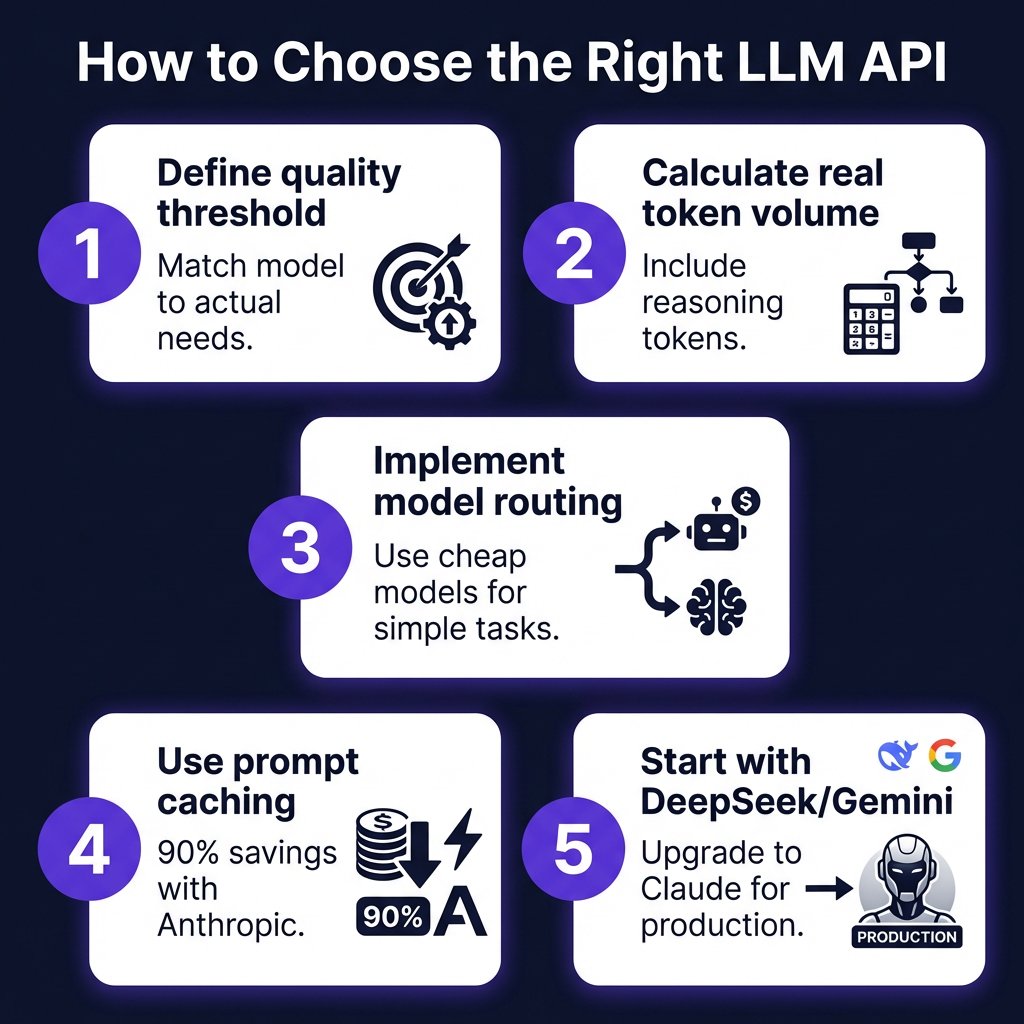
How to Choose the Right LLM for Your SaaS
Step 1: Define Your Quality Threshold
Not every application needs frontier-level reasoning. A customer support chatbot can run on Gemini Flash-Lite. A code review tool needs Claude Sonnet minimum. Be honest about what quality level actually moves the needle for your users.
Step 2: Calculate Real Token Volume
Most developers underestimate output tokens. Models with chain-of-thought reasoning (DeepSeek R1, Claude thinking mode) can generate 5-10x more output than input. A 100-token prompt can produce 1,000 tokens of reasoning before the final answer.
Step 3: Implement Model Routing
The optimal strategy isn’t picking one model — it’s routing requests intelligently:
- Simple queries → Gemini Flash-Lite ($0.10/1M)
- Standard tasks → DeepSeek V3.2 ($0.14/1M)
- Complex coding → Claude Sonnet 4.6 ($3.00/1M)
- Critical reasoning → Claude Opus 4.6 ($5.00/1M)
This hybrid approach can reduce costs by 80% while maintaining quality where it matters.
Step 4: Use Prompt Caching
Anthropic’s prompt caching delivers 90% savings on repeated context. If you’re sending the same system prompts or documentation context repeatedly, caching cuts costs from $3.00 to $0.30 per million tokens.
Hidden Costs to Watch
Sticker price isn’t the full story. Factor these into your calculations:
- Long context premiums: Claude Opus 4.6 doubles to $10/$37.50 per million when exceeding 200K tokens
- Reasoning tokens: Chain-of-thought models bill for every thinking token, not just final output
- Batch processing: OpenAI and Anthropic offer 50% discounts for batch API calls with 24-hour turnaround
- Rate limit tiers: Higher throughput often requires enterprise contracts with minimum commitments
Key Takeaways
- DeepSeek V3.2 delivers the best raw value at $0.14/1M input tokens — 71x cheaper than GPT-5
- Claude Sonnet 4.6 with caching is the production sweet spot for quality-conscious teams
- Gemini Flash-Lite offers a genuine free tier for MVPs and side projects
- Model routing beats single-model strategies — route simple tasks to cheap models, complex tasks to premium ones
- Benchmarks don’t tell the whole story — test with your actual use cases before committing
FAQ
Which LLM API is cheapest in 2026?
Gemini 2.5 Flash-Lite and GPT-4.1 Nano tie at $0.10 per million input tokens. DeepSeek V3.2 follows at $0.14. All three offer quality sufficient for many production use cases.
Is DeepSeek V3.2 reliable for production?
Yes, with caveats. The model performs well on standard benchmarks but has a smaller ecosystem than OpenAI or Anthropic. For non-critical applications and cost-sensitive startups, it’s production-ready. For enterprise systems requiring SLAs, Claude Sonnet or GPT-5 are safer bets.
How much can prompt caching save?
Anthropic’s prompt caching reduces cached input costs by 90%. If your application sends repeated system prompts or context, effective costs drop from $3.00 to $0.30 per million tokens on Sonnet 4.6.
What’s the best LLM for coding in 2026?
Claude Opus 4.6 leads on SWE-bench Verified at 80.9%, followed by Claude Sonnet 4.6 at 80.8%. For most development workflows, Sonnet offers the better value proposition at 1/8th the cost of Opus.
Should I use one model or multiple?
Multiple. A routing strategy that sends simple queries to Gemini Flash-Lite ($0.10/1M) and complex tasks to Claude Sonnet ($3.00/1M) typically reduces costs by 60-80% versus using a single premium model for everything.
Conclusion
The LLM API market in 2026 offers genuine choice. You don’t need to pay OpenAI prices to get quality results. DeepSeek V3.2 and Gemini Flash-Lite prove that capable models can cost under $0.50 per million tokens.
My recommendation: Start with DeepSeek V3.2 or Gemini Flash-Lite for prototyping. Move to Claude Sonnet 4.6 with caching for production. Reserve GPT-5 or Claude Opus for the 10% of tasks that actually need frontier-level reasoning.
Your runway will thank you.
Ready to build your AI-powered SaaS? Get started with Fungies — the Merchant of Record platform that handles payments, tax compliance, and checkout so you can focus on building.